Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Michael Paquier <michael(at)paquier(dot)xyz> |
| Cc: | Sami Imseih <samimseih(at)gmail(dot)com>, Ivan Bykov <I(dot)Bykov(at)modernsys(dot)ru>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET |
| Date: | 2025-03-25 06:47:10 |
| Message-ID: | CAApHDvreP04nhTKuYsPw0F-YN+4nr4f=L72SPeFb81jfv+2c7w@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Fri, 21 Mar 2025 at 18:45, Michael Paquier <michael(at)paquier(dot)xyz> wrote:
> Potential ideas about optimizing the branches seem worth
> investigating, I am not sure that I would be able to dig into that
> until the feature freeze gong, unfortunately, and it would be nice to
> fix this issue for this release. I'll see about doing some pgbench
> runs on my side, as well, with tpc-b Querys.
I've come up with a version of this that fixes the issue and improves
performance rather than regresses it. See attached.
This patch uses the same "ensure we jumble at least something when we
get a NULL" method, but works differently to anything previously
proposed here. Instead of modifying the jumble buffer each time we see
a NULL, the patch just increments a counter. It's only when something
else actually needs to append bytes to the buffer that we must flush
the pending NULLs to the buffer beforehand. I've opted to just write
the consecutive NULL count to the buffer. This allows the NULLs to be
appended more efficiently. This has the advantage of having to do very
little when we see NULL values, and would probably do well on your
"SELECT 1" test, which has lots of NULLs.
I've also performed a round of optimisations to the code:
1) The jumble size in AppendJumble should never be zero, so the while
(size > 0) loop can become a do while loop. This halves the size
checks for the normal non-overflow case.
2) Added inlined functions to jumble common field sizes. This saves
having to move the size into the appropriate register before calling
the AppendJumble function and reduces the size of the compiled code as
a result. It also allows the fast-path I added to AppendJumbleInternal
for the non-overflow case to work more efficiently as the memcpy can
transformed into fewer instructions due to the size being both known
and small enough to perform the copy in a single instruction. This
previously didn't work since part_size is a variable the inlined
function. With the fast-path, "size" is used, which is a compile-time
const to the inlined function.
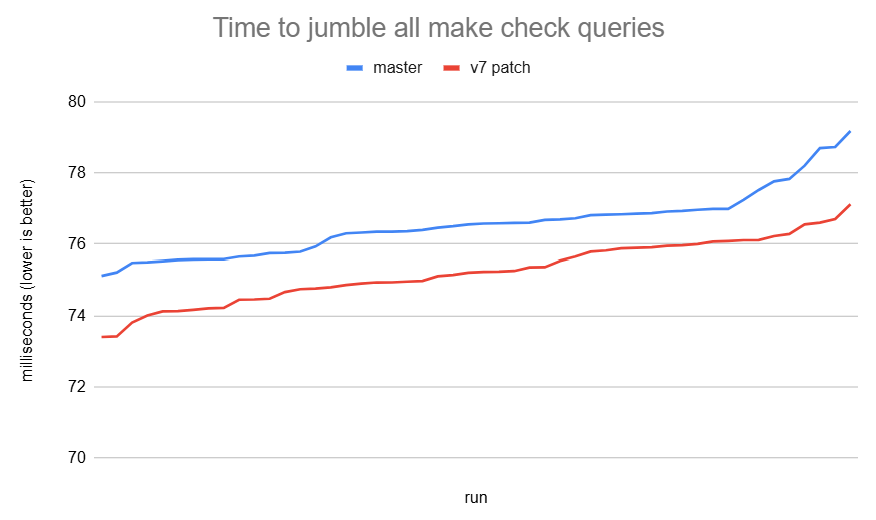
I tested the performance of this using the patch from [1] and running
"make check" 50 times. This gave me the total time spent jumbling all
of the make check queries. I sorted the results by time and graphed
them in the attached graph. The patched version is on average 1.73%
*faster* than master on my AMD 3990x machine:
master: 76.564 milliseconds
v7 patch 75.236 milliseconds
It should be possible to still add the total_jumble_len stuff to this
in assert builds with zero extra overhead in non-assert builds, which
I think should address your concern with custom jumble functions not
jumbling anything. I can adjust accordingly if you're happy to use the
method I'm proposing.
The tests done were in a version of master prior to 5ac462e2b. I've
not yet studied if anything needs to be adjusted to account for that
commit.
David
[1] https://www.postgresql.org/message-id/attachment/174042/jumbletime.patch.txt
| Attachment | Content-Type | Size |
|---|---|---|
| v7-0001-Fix-query-jumbling-to-account-for-NULL-nodes.patch | application/octet-stream | 9.2 KB |
|
image/png | 25.0 KB |
In response to
- Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET at 2025-03-21 05:45:09 from Michael Paquier
Responses
- RE: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET at 2025-03-25 08:14:44 from Bykov Ivan
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Jeff Davis | 2025-03-25 06:53:33 | Re: Statistics Import and Export |
| Previous Message | Amit Kapila | 2025-03-25 06:44:53 | Re: Fix slot synchronization with two_phase decoding enabled |