Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Bykov Ivan <i(dot)bykov(at)modernsys(dot)ru> |
| Cc: | Michael Paquier <michael(at)paquier(dot)xyz>, Sami Imseih <samimseih(at)gmail(dot)com>, "pgsql-hackers(at)postgresql(dot)org" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET |
| Date: | 2025-03-25 12:11:45 |
| Message-ID: | CAApHDvoyW+ptR4LMOEE4mkXvJx-bxWMJu56HJ9x8RiHsw3o3Uw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Tue, 25 Mar 2025 at 21:14, Bykov Ivan <i(dot)bykov(at)modernsys(dot)ru> wrote:
> As I can see, your patch has the same idea as my v2-0001-Query-ID-Calculation-Fix-Variant-B.patch from [1].
> I think it would be better to extract the jumble buffer update with hash calculation into a function
> (CompressJumble in my patch). This will result in fewer changes to the source code.
> We can also simply dump the null count to the buffer when we encounter a non-null field
> (which will be processed in AppendJumble, indeed).
>
> What do your thing about my patch (v2-0001-Query-ID-Calculation-Fix-Variant-B.patch)?
Seemingly, I missed that one. I agree with the general method being
suitable, which might not be surprising since I ended up at the same
conclusion independently.
I quite like your CompressJumble() idea, but I don't know that it
amounts to any compiled code changes.
I think it's a bit strange that you're flushing the pending nulls to
the jumble buffer after jumbling the first non-null. I think it makes
much more sense to do it before as I did, otherwise, you're
effectively jumbling fields out of order.
I see you opted to only jumble the low-order byte of the pending null
counter. I used the full 4 bytes as I don't think the extra 3 bytes is
a problem. Witrh v7 the memcpy to copy the pending_nulls into the
buffer is inlined into a single instruction. It's semi-conceivable
that you could have more than 255 NULLs given that a List can contain
Nodes. I don't know if we ever have any NULL items in Lists at the
moment, but I don't think that that's disallowed. I'd feel much safer
taking the full 4 bytes of the counter to help prevent future
surprises.
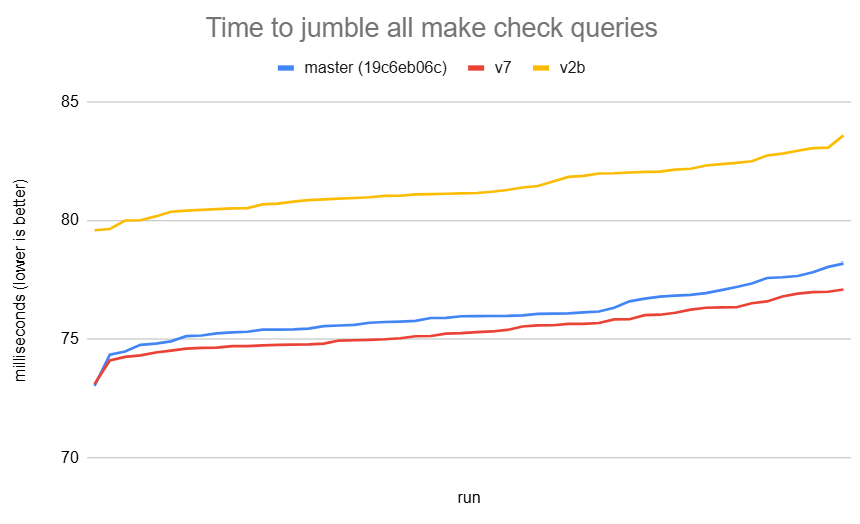
Aside from that, v2b still has the performance regression issue that
we're trying to solve. I did a fresh run of master as of 19c6eb06c and
tested v7 and v2b. Here are the average times it took to jumble all
the make check queries over 50 runs;
master: 76.052 ms
v7: 75.422 ms
v2b: 81.391 ms
I also attached a graph.
I'm happy to proceed with the v7 version. I'm also happy to credit you
as the primary author of it, given that you came up with the v2b
patch. It might be best to extract the performance stuff that's in v7
and apply that separately from the bug fix. If you're still interested
and have time in the next 7 hours to do it, would you be able to split
the v7 as described, making v8-0001 as the bug fix and v8-0002 as the
performance stuff? If so, could you also add the total_jumble_len to
v8-0001 like Michael's last patch had, but adjust so it's only
maintained for Assert builds. Michael is quite keen on having more
assurance that custom jumble functions don't decide to forego any
jumbling.
If you don't have time, I'll do it in my morning (UTC+13).
Thanks
David
> [1] https://www.postgresql.org/message-id/5ac172e0b77a4baba50671cd1a15285f%40localhost.localdomain
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 27.3 KB |
In response to
- RE: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET at 2025-03-25 08:14:44 from Bykov Ivan
Responses
- Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET at 2025-03-25 22:56:50 from David Rowley
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | John Naylor | 2025-03-25 13:04:10 | Re: Improve CRC32C performance on SSE4.2 |
| Previous Message | Ashutosh Bapat | 2025-03-25 12:09:19 | Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning |