we find crash reson
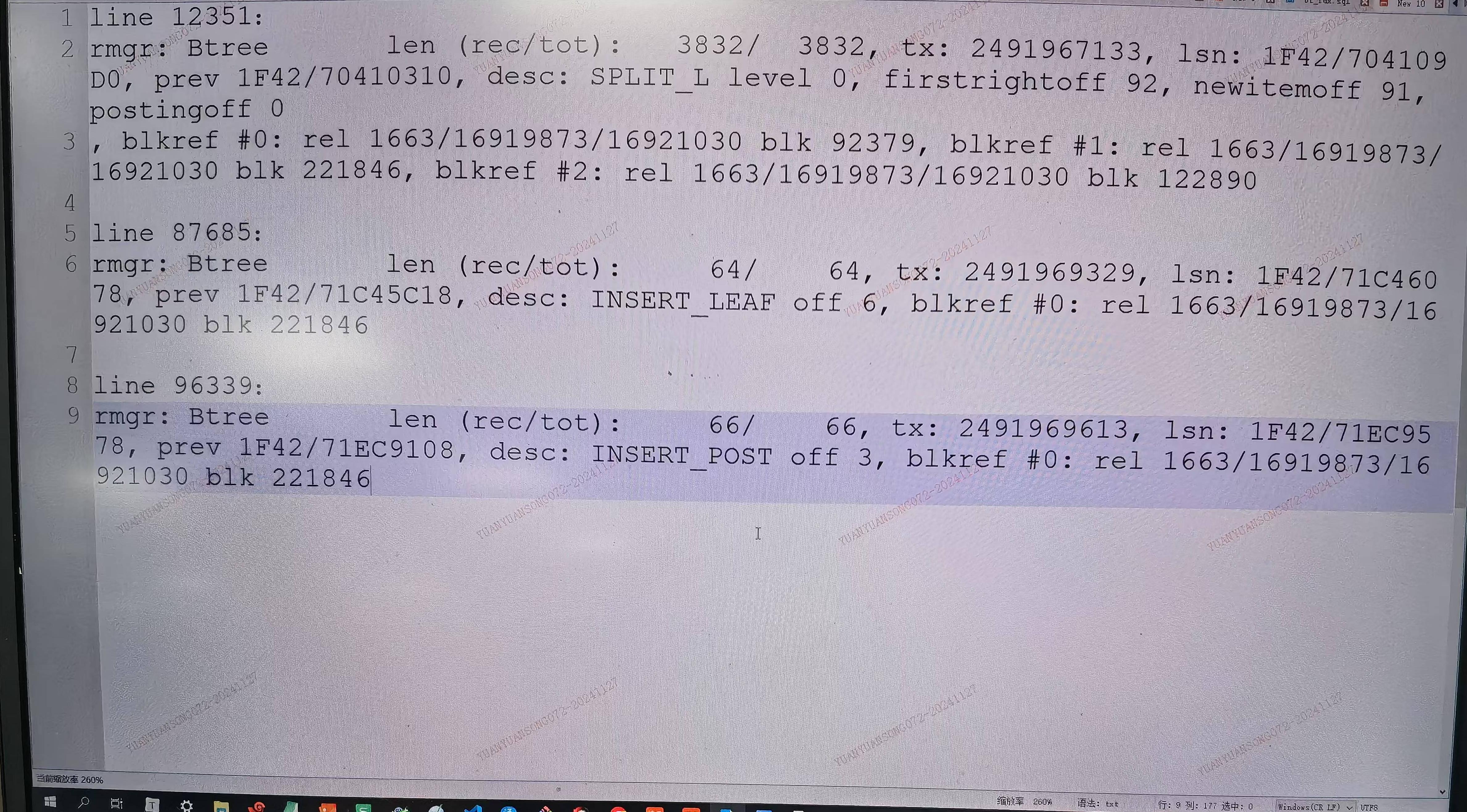
We have identified the cause of the crash: it was due to the XLOG_BTREE_INSERT_POST XLOG having an OffsetNumber offnum that was one less than what was stored in the index. I experimented with adding +1, and the index data remained normal in both cases. This issue is likely caused by concurrent operations on the B-tree, and upon reviewing the corresponding WAL logs, we found SPLIT_L and INSERT_LEAF operations on the same block before the crash. This might be a bug. I'm not sure if there's a related fix.
At 2024-11-21 23:58:03, "Peter Geoghegan" <pg(at)bowt(dot)ie> wrote:
>On Thu, Nov 21, 2024 at 10:03 AM yuansong <yyuansong(at)126(dot)com> wrote:
>> Should nhtids be less than or equal to IndexTupleSize(oposting)?
>> Why is nhtids larger than IndexTupleSize(oposting) ? I think there should be an error in the master host writing the wal log.
>> Does anyone know when this will happen?
>
>It'll happen whenever there is a certain kind of data corruption.
>
>There were complaints about issues like this in the past. But those
>complaints seem to have gone away when more hardening was added to the
>code that runs during original execution (not the REDO routine code,
>which can only do what it is told to do by the WAL record).
>
>You're using PostgreSQL 13.2, which is a very old point release that
>lacks this hardening -- the current 13 point release is 13.18, so
>you're missing a lot. Had you been on a later point release you'd very
>probably have still had the issue with corruption (which could be from
>bad hardware), but you likely would have avoided the problem with the
>REDO routine crashing like this.
>
>--
>Peter Geoghegan
{kind=link}