| From: | Tomas Vondra <tomas(at)vondra(dot)me> |
|---|---|
| To: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | should we have a fast-path planning for OLTP starjoins? |
| Date: | 2025-02-04 14:00:49 |
| Message-ID: | 1ea167aa-457d-422a-8422-b025bb660ef3@vondra.me |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
While running benchmarks for my "performance over 20 years" talk [1],
I've been been also looking for common cases that don't perform well
(and thus might be a good topic for optimization, with significant
speedup helping a lot of deployments).
One such simple example that I ran into is "OLTP starjoin". You're
probably familiar with star schema in the DSS field [2], as a large fact
table with many small-ish dimensions. The OLTP variant is exactly the
same thing, but with selective WHERE conditions on the fact table.
So you can imagine it as a query of this shape:
SELECT * FROM fact_table f
JOIN dim1 ON (f.id1 = dim1.id)
JOIN dim2 ON (f.id2 = dim2.id)
JOIN dim3 ON (f.id3 = dim3.id)
...
WHERE f.id = 2398723;
This is a surprisingly common query pattern in OLTP applications, thanks
to normalization. For example the "fact" may be a table of transactions
with some basic common details, dimensions are additional "details" for
special types of transactions. When loading info about a transaction of
unknown type, this allows you to load everything at once.
Or maybe the fact table is "users" and the dimensions have all kinds of
info about the user (address, primary e-mail address, balance, ...).
Anyway, this pattern is quite common, yet it performs quite poorly.
Let's join a fact table with 10 dimensions - see the attached create
script to build such schema, and the test.sql script for pgbench.
On my new ryzen machine, this peaks at about ~16k tps with 16 clients.
The machine can easily do 1M tps in read-only pgbench, for example. And
if you increase the join_collapse_limit to 12 (because the default 8 is
not enough for the 10 dimensions), the throughput drops to ~2k tps.
That's not great.
AFAIK this is a consequence of the star joins allowing arbitrary join
order of the dimensions - those only have join conditions to the fact
relation, so it allows many join orders. So exploring them takes a lot
of time, of course.
But for starjoins, a lot of this is not really needed. In the simplest
case (no conditions on dimensions etc) it does not really matter in what
order we join those, and filters on dimensions make it only a little bit
more complicated (join the most selective first).
So I've been wondering how difficult would it be to have a special
fast-path mode for starjoins, completely skipping most of this. I
cobbled together a WIP/PoC patch (attached) on the way from FOSDEM, and
it seems to help quite a bit.
I definitely don't claim the patch is correct for all interesting cases,
just for the example query. And I'm sure there's plenty of things to fix
or improve (e.g. handling of outer joins, more complex joins, ...).
But these are the rough results for 1 and 16 clients:
build 1 16
--------------------------------------
master 1600 16000
patched 4400 46000
So that about triples the throughput. If you bump join_collapse_limit to
12, it gets even clearer
build 1 16
--------------------------------------
master 200 2000
patched 4500 48000
That's a 20x improvement - not bad. Sure, this is on a tiny dataset, and
with larger data sets it might need to do I/O, diminishing the benefits.
It's just an example to demonstrate the benefits.
If you want to try the patch, there's a new GUC enable_starjoin to
enable this optimization (off by default).
The patch does roughly this:
1) It tries to detect a "star join" before doing the full join order
search. It simply looks for the largest relation (not considering the
conditions), and assumes it's a fact. And then it searches for relations
that only join to the fact - those are the dimensions.
2) With the relations found in (1) it just builds the join relations
directly (one per level), without exploring all the possibilities. This
is where the speedup comes from.
3) If there are additional relations, those are then left to the regular
join order search algorithm.
There's a lot of stuff that could / should be improved on the current
patch. For (1) we might add support for more complex cases with
snowflake schemas [3] or with multiple fact tables. At the same time (1)
needs to be very cheap, so that it does not regress every non-starjoin
query.
For (2) it might pick a particular order we join the dimensions (by
size, selectivity, ...), and it might consider whether to join them
before/after the other relations.
FWIW I suspect there's a fair amount of research papers looking at
starjoins and what is the optimal plan for such queries, but I didn't
have time to look at that yet. Pointers welcome!
But the bigger question is whether it makes sense to have such fast-path
modes for certain query shapes. The patch "hard-codes" the planning for
starjoin queries, but we clearly can't do that for every possible join
shape (because then why have dynamic join search at all?).
I do think starjoins might be sufficiently unique / special to justify
this, but maybe it would be possible to instead improve the regular join
order search to handle this case better? I don't have a very clear idea
what would that look like, though :-(
I did check what do some other databases do, and they often have some
sort of "hint" to nudge the let the optimizer know this is a starjoin.
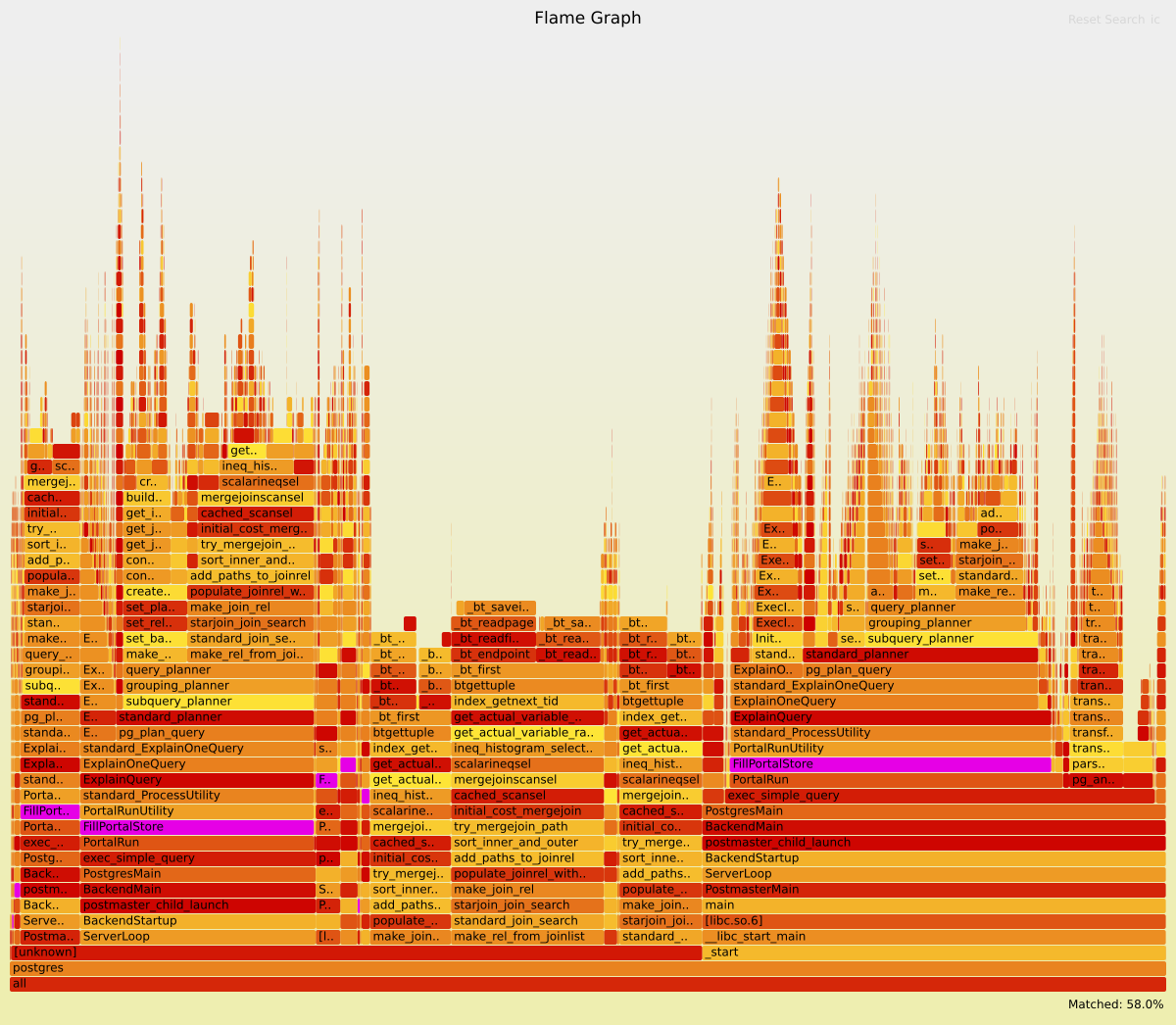
I also looked at what are the main bottlenecks with the simpler starjoin
planning enabled - see the attached flamegraphs. The optimizations seem
to break the stacktraces a bit, so there's a svg for "-O0 -ggdb3" too,
that doesn't have this issue (the shape is different, but the conclusion
are about the same).
In both cases about 40% of the time is spent in initial_cost_mergejoin,
which seems like a lot - and yes, disabling mergejoin doubles the
throughput. And most of the cost is in get_actual_variable_range,
looking up the range in the btrees. That seems like a lot, considering
the indexes are perfectly clean (we used to have problems with deleted
tuples, but this is not the case). I wonder if maybe we could start
caching this kind of info somewhere.
regards
[1]
https://www.postgresql.eu/events/pgconfeu2024/schedule/session/5585-performance-archaeology/
[2] https://en.wikipedia.org/wiki/Star_schema
[3] https://en.wikipedia.org/wiki/Snowflake_schema
--
Tomas Vondra
| Attachment | Content-Type | Size |
|---|---|---|
| starjoin.sql | application/sql | 452 bytes |
| starjoin-create.sql | application/sql | 2.3 KB |
| 0001-WIP-simplified-planning-of-starjoins.patch | text/x-patch | 11.6 KB |
| starjoin-optim.png | image/png | 375.9 KB |
| starjoin-no-optim.png | image/png | 272.0 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Alvaro Herrera | 2025-02-04 14:22:47 | Re: NOT ENFORCED constraint feature |
| Previous Message | Peter Eisentraut | 2025-02-04 13:56:52 | Re: NOT ENFORCED constraint feature |
{kind=link}
{kind=link}