| From: | "Zhou, Zhiguo" <zhiguo(dot)zhou(at)intel(dot)com> |
|---|---|
| To: | Japin Li <japinli(at)hotmail(dot)com> |
| Cc: | Yura Sokolov <y(dot)sokolov(at)postgrespro(dot)ru>, wenhui qiu <qiuwenhuifx(at)gmail(dot)com>, "pgsql-hackers(at)postgresql(dot)org" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: [RFC] Lock-free XLog Reservation from WAL |
| Date: | 2025-02-14 08:41:35 |
| Message-ID: | f6d3c88c-a3a3-4b1d-9af4-69d119ef250e@intel.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 2/11/2025 9:25 AM, Japin Li wrote:
> On Mon, 10 Feb 2025 at 22:12, "Zhou, Zhiguo" <zhiguo(dot)zhou(at)intel(dot)com> wrote:
>> On 2/5/2025 4:32 PM, Japin Li wrote:
>>> On Mon, 27 Jan 2025 at 17:30, "Zhou, Zhiguo" <zhiguo(dot)zhou(at)intel(dot)com> wrote:
>>>> On 1/26/2025 10:59 PM, Yura Sokolov wrote:
>>>>> 24.01.2025 12:07, Japin Li пишет:
>>>>>> On Thu, 23 Jan 2025 at 21:44, Japin Li <japinli(at)hotmail(dot)com> wrote:
>>>>>>> On Thu, 23 Jan 2025 at 15:03, Yura Sokolov
>>>>>>> <y(dot)sokolov(at)postgrespro(dot)ru> wrote:
>>>>>>>> 23.01.2025 11:46, Japin Li пишет:
>>>>>>>>> On Wed, 22 Jan 2025 at 22:44, Japin Li <japinli(at)hotmail(dot)com> wrote:
>>>>>>>>>> On Wed, 22 Jan 2025 at 17:02, Yura Sokolov
>>>>>>>>>> <y(dot)sokolov(at)postgrespro(dot)ru> wrote:
>>>>>>>>>>> I believe, I know why it happens: I was in hurry making v2 by
>>>>>>>>>>> cherry-picking internal version. I reverted some changes in
>>>>>>>>>>> CalcCuckooPositions manually and forgot to add modulo
>>>>>>>>>>> PREV_LINKS_HASH_CAPA.
>>>>>>>>>>>
>>>>>>>>>>> Here's the fix:
>>>>>>>>>>>
>>>>>>>>>>> pos->pos[0] = hash % PREV_LINKS_HASH_CAPA;
>>>>>>>>>>> - pos->pos[1] = pos->pos[0] + 1;
>>>>>>>>>>> + pos->pos[1] = (pos->pos[0] + 1) % PREV_LINKS_HASH_CAPA;
>>>>>>>>>>> pos->pos[2] = (hash >> 16) % PREV_LINKS_HASH_CAPA;
>>>>>>>>>>> - pos->pos[3] = pos->pos[2] + 2;
>>>>>>>>>>> + pos->pos[3] = (pos->pos[2] + 2) % PREV_LINKS_HASH_CAPA;
>>>>>>>>>>>
>>>>>>>>>>> Any way, here's v3:
>>>>>>>>>>> - excess file "v0-0001-Increase..." removed. I believe it was source
>>>>>>>>>>> of white-space apply warnings.
>>>>>>>>>>> - this mistake fixed
>>>>>>>>>>> - more clear slots strategies + "8 positions in two
>>>>>>>>>>> cache-lines" strategy.
>>>>>>>>>>>
>>>>>>>>>>> You may play with switching PREV_LINKS_HASH_STRATEGY to 2 or 3
>>>>>>>>>>> and see
>>>>>>>>>>> if it affects measurably.
>>>>>>>>>>
>>>>>>>>>> Thanks for your quick fixing. I will retest it tomorrow.
>>>>>>>>> Hi, Yura Sokolov
>>>>>>>>> Here is my test result of the v3 patch:
>>>>>>>>> | case | min | avg | max
>>>>>>>>> |
>>>>>>>>> |-------------------------------+------------+------------
>>>>>>>>> +------------|
>>>>>>>>> | master (44b61efb79) | 865,743.55 | 871,237.40 |
>>>>>>>>> 874,492.59 |
>>>>>>>>> | v3 | 857,020.58 | 860,180.11 |
>>>>>>>>> 864,355.00 |
>>>>>>>>> | v3 PREV_LINKS_HASH_STRATEGY=2 | 853,187.41 | 855,796.36 |
>>>>>>>>> 858,436.44 |
>>>>>>>>> | v3 PREV_LINKS_HASH_STRATEGY=3 | 863,131.97 | 864,272.91 |
>>>>>>>>> 865,396.42 |
>>>>>>>>> It seems there are some performance decreases :( or something I
>>>>>>>>> missed?
>>>>>>>>>
>>>>>>>>
>>>>>>>> Hi, Japin.
>>>>>>>> (Excuse me for duplicating message, I found I sent it only to you
>>>>>>>> first time).
>>>>>>>>
>>>>>>> Never mind!
>>>>>>>
>>>>>>>> v3 (as well as v2) doesn't increase NUM_XLOGINSERT_LOCKS itself.
>>>>>>>> With only 8 in-progress inserters spin-lock is certainly better
>>>>>>>> than any
>>>>>>>> more complex solution.
>>>>>>>>
>>>>>>>> You need to compare "master" vs "master + NUM_XLOGINSERT_LOCKS=64" vs
>>>>>>>> "master + NUM_XLOGINSERT_LOCKS=64 + v3".
>>>>>>>>
>>>>>>>> And even this way I don't claim "Lock-free reservation" gives any
>>>>>>>> profit.
>>>>>>>>
>>>>>>>> That is why your benchmarking is very valuable! It could answer, does
>>>>>>>> we need such not-small patch, or there is no real problem at all?
>>>>>>>>
>>>>>>
>>>>>> Hi, Yura Sokolov
>>>>>>
>>>>>> Here is the test result compared with NUM_XLOGINSERT_LOCKS and the
>>>>>> v3 patch.
>>>>>>
>>>>>> | case | min | avg |
>>>>>> max | rate% |
>>>>>> |-----------------------+--------------+--------------+--------------
>>>>>> +-------|
>>>>>> | master (4108440) | 891,225.77 | 904,868.75 |
>>>>>> 913,708.17 | |
>>>>>> | lock 64 | 1,007,716.95 | 1,012,013.22 |
>>>>>> 1,018,674.00 | 11.84 |
>>>>>> | lock 64 attempt 1 | 1,016,716.07 | 1,017,735.55 |
>>>>>> 1,019,328.36 | 12.47 |
>>>>>> | lock 64 attempt 2 | 1,015,328.31 | 1,018,147.74 |
>>>>>> 1,021,513.14 | 12.52 |
>>>>>> | lock 128 | 1,010,147.38 | 1,014,128.11 |
>>>>>> 1,018,672.01 | 12.07 |
>>>>>> | lock 128 attempt 1 | 1,018,154.79 | 1,023,348.35 |
>>>>>> 1,031,365.42 | 13.09 |
>>>>>> | lock 128 attempt 2 | 1,013,245.56 | 1,018,984.78 |
>>>>>> 1,023,696.00 | 12.61 |
>>>>>> | lock 64 v3 | 1,010,893.30 | 1,022,787.25 |
>>>>>> 1,029,200.26 | 13.03 |
>>>>>> | lock 64 attempt 1 v3 | 1,014,961.21 | 1,019,745.09 |
>>>>>> 1,025,511.62 | 12.70 |
>>>>>> | lock 64 attempt 2 v3 | 1,015,690.73 | 1,018,365.46 |
>>>>>> 1,020,200.57 | 12.54 |
>>>>>> | lock 128 v3 | 1,012,653.14 | 1,013,637.09 |
>>>>>> 1,014,358.69 | 12.02 |
>>>>>> | lock 128 attempt 1 v3 | 1,008,027.57 | 1,016,849.87 |
>>>>>> 1,024,597.15 | 12.38 |
>>>>>> | lock 128 attempt 2 v3 | 1,020,552.04 | 1,024,658.92 |
>>>>>> 1,027,855.90 | 13.24 |
>>>>
>>>> The data looks really interesting and I recognize the need for further
>>>> investigation. I'm not very familiar with BenchmarkSQL but we've done
>>>> similar tests with HammerDB/TPCC by solely increasing
>>>> NUM_XLOGINSERT_LOCKS from 8 to 128, and we observed a significant
>>>> performance drop of ~50% and the cycle ratio of spinlock acquisition
>>>> (s_lock) rose to over 60% of the total, which is basically consistent
>>>> with the previous findings in [1].
>>>>
>>>> Could you please share the details of your test environment, including
>>>> the device, configuration, and test approach, so we can collaborate on
>>>> understanding the differences?
>>> Sorry for the late reply. I'm on my vacation.
>>> I use Hygon C86 7490 64-core, it has 8 NUMA nodes with 1.5T memory,
>>> and
>>> I use 0-3 run the database, and 4-7 run the BenchmarkSQL.
>>> Here is my database settings:
>>> listen_addresses = '*'
>>> max_connections = '1050'
>>> shared_buffers = '100GB'
>>> work_mem = '64MB'
>>> maintenance_work_mem = '512MB'
>>> max_wal_size = '50GB'
>>> min_wal_size = '10GB'
>>> random_page_cost = '1.1'
>>> wal_buffers = '1GB'
>>> wal_level = 'minimal'
>>> max_wal_senders = '0'
>>> wal_sync_method = 'open_datasync'
>>> wal_compression = 'lz4'
>>> track_activities = 'off'
>>> checkpoint_timeout = '1d'
>>> checkpoint_completion_target = '0.95'
>>> effective_cache_size = '300GB'
>>> effective_io_concurrency = '32'
>>> update_process_title = 'off'
>>> password_encryption = 'md5'
>>> huge_pages = 'on'
>>>
>>>>> Sorry for pause, it was my birthday, so I was on short vacation.
>>>>> So, in total:
>>>>> - increasing NUM_XLOGINSERT_LOCKS to 64 certainly helps
>>>>> - additional lock attempts seems to help a bit in this benchmark,
>>>>> but it helps more in other (rather synthetic) benchmark [1]
>>>>> - my version of lock-free reservation looks to help a bit when
>>>>> applied alone, but look strange in conjunction with additional
>>>>> lock attempts.
>>>>> I don't see small improvement from my version of Lock-Free
>>>>> reservation
>>>>> (1.1% = 1023/1012) pays for its complexity at the moment.
>>>>
>>>> Due to limited hardware resources, I only had the opportunity to
>>>> measure the performance impact of your v1 patch of the lock-free hash
>>>> table with 64 NUM_XLOGINSERT_LOCKS and the two lock attempt patch. I
>>>> observed an improvement of *76.4%* (RSD: 4.1%) when combining them
>>>> together on the SPR with 480 vCPUs. I understand that your test
>>>> devices may not have as many cores, which might be why this
>>>> optimization brings an unnoticeable impact. However, I don't think
>>>> this is an unreal problem. In fact, this issue was raised by our
>>>> customer who is trying to deploy Postgres on devices with hundreds of
>>>> cores, and I believe the resolution of this performance issue would
>>>> result in real impacts.
>>>>
>>>>> Probably, when other places will be optimized/improved, it will pay
>>>>> more.
>>>>> Or probably Zhiguo Zhou's version will perform better.
>>>>>
>>>>
>>>> Our primary difference lies in the approach to handling the prev-link,
>>>> either via the hash table or directly within the XLog buffer. During
>>>> my analysis, I didn't identify significant hotspots in the hash table
>>>> functions, leading me to believe that both implementations should
>>>> achieve comparable performance improvements.
>>>>
>>>> Following your advice, I revised my implementation to update the
>>>> prev-link atomically and resolved the known TAP tests. However, I
>>>> encountered the last failure in the recovery/t/027_stream_regress.pl
>>>> test. Addressing this issue might require a redesign of the underlying
>>>> writing convention of XLog, which I believe is not necessary,
>>>> especially since your implementation already achieves the desired
>>>> performance improvements without suffering from the test failures. I
>>>> think we may need to focus on your implementation in the next phase.
>>>>
>>>>> I think, we could measure theoretical benefit by completely ignoring
>>>>> fill of xl_prev. I've attached patch "Dumb-lock-free..." so you could
>>>>> measure. It passes almost all "recovery" tests, though fails two
>>>>> strictly dependent on xl_prev.
>>>>
>>>
>>>> I currently don't have access to the high-core-count device, but I
>>>> plan to measure the performance impact of your latest patch and the
>>>> "Dump-lock-free..." patch once I regain access.
>>>>> [1] https://postgr.es/m/3b11fdc2-9793-403d-
>>>>> b3d4-67ff9a00d447%40postgrespro.ru
>>>>> ------
>>>>> regards
>>>>> Yura
>>>>
>>>> Hi Yura and Japin,
>>>>
>>>> Thanks so much for your recent patch works and discussions which
>>>> inspired me a lot! I agree with you that we need to:
>>>> - Align the test approach and environment
>>>> - Address the motivation and necessity of this optimization
>>>> - Further identify the optimization opportunities after applying
>>>> Yura's patch
>>>>
>>>> WDYT?
>>>>
>>>> [1]
>>>> https://www.postgresql.org/message-id/6ykez6chr5wfiveuv2iby236mb7ab6fqwpxghppdi5ugb4kdyt%40lkrn4maox2wj
>>>>
>>>> Regards,
>>>> Zhiguo
>>>
>>
>> Hi Japin,
>>
>> Apologies for the delay in responding—I've just returned from
>> vacation. To move things forward, I'll be running the BenchmarkSQL
>> workload on my end shortly.
>>
>> In the meantime, could you run the HammerDB/TPCC workload on your
>> device? We've observed significant performance improvements with this
>> test, and it might help clarify whether the discrepancies we're seeing
>> stem from the workload itself. Thanks!
>>
>
> Sorry, I currently don't have access to the test device, I will try to test
> it if I can regain access.
>
Good day, Yura and Japin!
I recently acquired the SUT device again and had the opportunity to
conduct performance experiments using the TPC-C benchmark (pg_count_ware
757, vu 256) with HammerDB on an Intel CPU with 480 vCPUs. Below are the
results and key observations:
+----------------+-------------+------------+-------------+------------+
| Version | NOPM | NOPM Gain% | TPM | TPM(Gain%) |
+----------------+-------------+------------+-------------+------------+
| master(b4a07f5)| 1,681,233 | 0.0% | 3,874,491 | 0.0% |
| 64-lock | 643,853 | -61.7% | 1,479,647 | -61.8% |
| 64-lock-v4 | 2,423,972 | 44.2% | 5,577,580 | 44.0% |
| 128-lock | 462,993 | -72.5% | 1,064,733 | -72.5% |
| 128-lock-v4 | 2,468,034 | 46.8% | 5,673,349 | 46.4% |
+----------------+-------------+------------+-------------+------------+
- Though the baseline (b4a07f5) has improved compared to when we created
this mailing list, we still achieve 44% improvement with this optimization.
- Increasing NUM_XLOGINSERT_LOCKS solely to 64/128 leads to severe
performance regression due to intensified lock contention.
- Increasing NUM_XLOGINSERT_LOCKS and applying the lock-free xlog
insertion optimization jointly improve overall performance.
- 64 locks seems the sweet spot for achieving the most performance
improvement.
I also executed the same benchmark, TPCC, with BenchmarkSQL (I'm not
sure if the difference of their implementation of TPCC would lead to
some performance gap). I observed that:
- The performance indicator (NOPM) shows differences of several
magnitudes compared to Japin's results.
- NOPM/TPM seems insensitive to code changes (lock count increase,
lock-free algorithm), which is quite strange.
- Possible reasons may include: 1) scaling parameters [1] are not
aligned, 2) test configuration did not reach the pain point of the XLog
insertions.
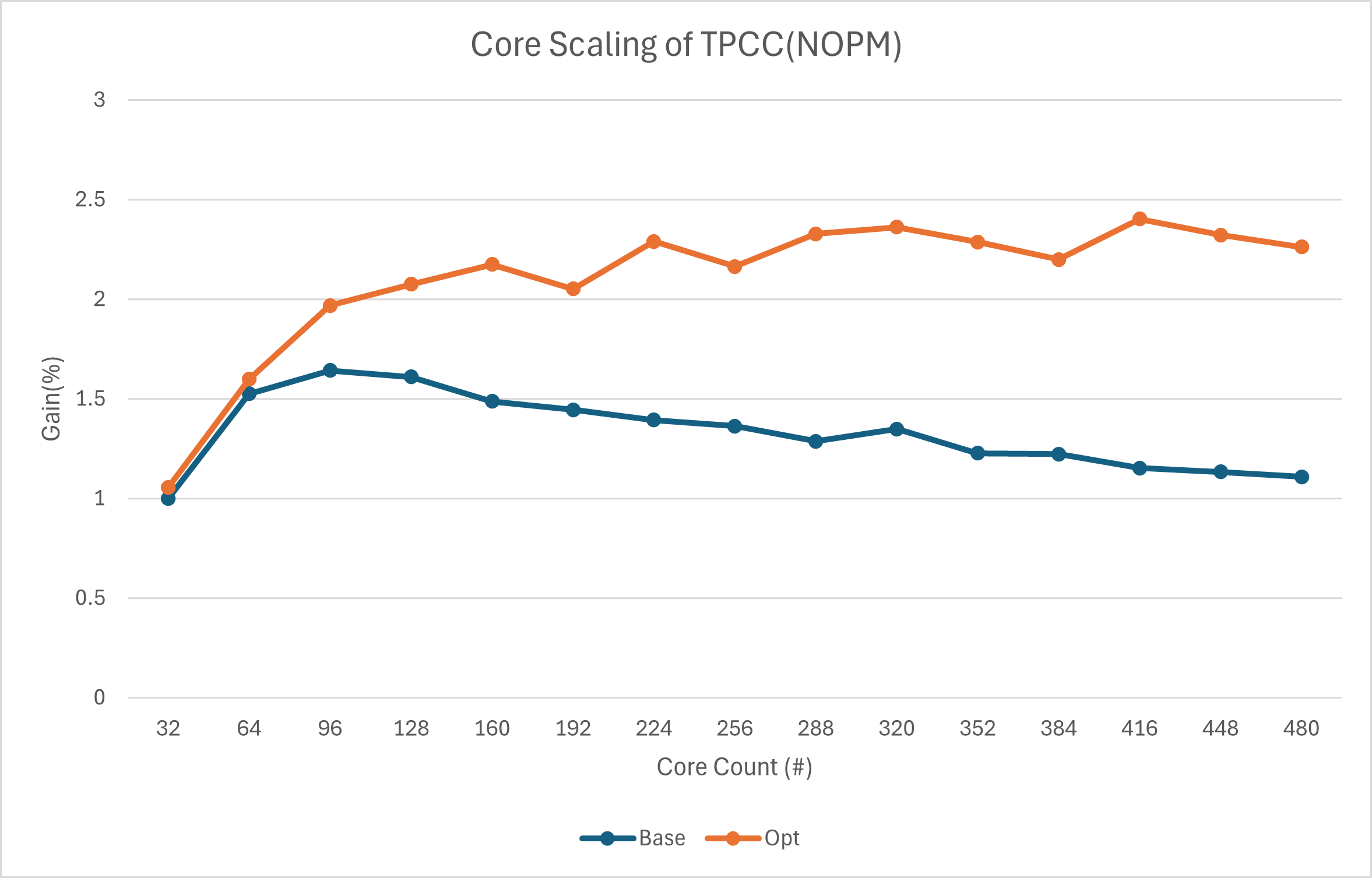
And I noticed a 64-core device (32 cores for the server) was used in
Japin's test. In our previous core-scaling test (attached), 32/64 cores
may not be enough to show the impact of the optimization, I think that
would be one of the reason why Japin observed minimal impact from the
lock-free optimization.
In summary, I think:
- The TPC-C benchmark (pg_count_ware 757, vu 256) with HammerDB
effectively reflects performance in XLog insertions.
- This test on a device with hundreds of cores reflects a real user
scenario, making it a significant consideration.
- The lock-free algorithm with the lock count increased to 64 can bring
significant performance improvements.
So I propose to continue the code review process for this optimization
patch. WDYT?
Regards,
Zhiguo
[1]
https://github.com/pgsql-io/benchmarksql/blob/master/docs/PROPERTIES.md#scaling-parameters
| Attachment | Content-Type | Size |
|---|---|---|
| pg-tpcc-core-scaling-lock-free.png | image/png | 83.7 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Bertrand Drouvot | 2025-02-14 08:57:49 | Re: Move wal_buffers_full to WalUsage (and report it in pgss/explain) |
| Previous Message | Masahiko Sawada | 2025-02-14 08:38:24 | Re: Parallel heap vacuum |
{kind=link}