PoC. The saving of the compiled jit-code in the plan cache
| From: | Vladlen Popolitov <v(dot)popolitov(at)postgrespro(dot)ru> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org, hukutoc(at)gmail(dot)com, andres(at)anarazel(dot)de |
| Subject: | PoC. The saving of the compiled jit-code in the plan cache |
| Date: | 2025-02-13 09:01:05 |
| Message-ID: | d29cbb6d453b24464b8d7bdab78fc5e2@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Dear colleagues,
I implemented the patch to store in the plan cache an already compiled
jit
code. If a query is executed many times, the query time can be decreased
by
20-30% for long queries with big share of expressions in the code.
This patch can be applied to the current master and passes tests, but it
is
only the Proof of the Concept, and I need to get opinions and advice for
nexts
steps. It is not ready for commitfest, does not cover all scenarios
(craches
in some sutuation that need special solution), and source code is not
clean.
The code source has removed old code marked by // comments to easier
compare,
what was changed, especially in llvmjit_expr.c and llvmjit_deform.c
Implementation details.
1. Changes in jit-code generation.
a) the load of the absolute address (as const) changed to the load of
this
address from a struct member:
old version:
v_resvaluep = l_ptr_const(op->resvalue, l_ptr(TypeSizeT));
new version
v_resvaluep = l_load_struct_gep( b, g->StructExprEvalStep, v_op,
FIELDNO_EXPREVALSTEP_RESVALUE, "v_resvaluep");
b) the load of the absolute address or the value from union changed to
the load of the union value using the offset of the union member
old version
fcinfo - the union member value
v_fcinfo = l_ptr_const(fcinfo, l_ptr(g->StructFunctionCallInfoData));
new version
v_fcinfo = l_load_member_value_by_offset(b,lc, v_op,
l_ptr(g->StructFunctionCallInfoData), offsetof(ExprEvalStep,
d.func.fcinfo_data ));
c) every cached plan has own LLVM-context and 1 module in it. As result,
some functions require context parameter to correctly address it instead
of the global llvm_context variable.
d) llvm_types moved from global variables to the struct LLVMJitTypes.
Not cached queries use old setup, but all types definitions are stored
in global struct LLVMJitTypes llvm_jit_types_struct, instead of many
global variables. Chached queries allocate struct LLVMJitTypes during
query
executon, and pfree it when cached plan is deallocated. llvm_types
module is
read for every cached statement (not 1 time during global context
creation).
e) llvm_function_reference still uses l_ptr_const with the absolute
address
of the function, it needs to be checked, as the function can change
address.
f) new GUC variabe jit_cached is added, off by default.
2. Changes in cached plan.
To store cached context I use struct PlannedStmt (in ExprState
state->parent->state->es_plannedstmt).
New member struct CachedJitContext *jit_context added to store
information
about jit context. In new plans this field in NULL. If plan is stored to
cache,
it filled by CACHED_JITCONTEXT_EMPTY and replaced by actual jit context
pointer
in llvmjit_expr.c .
When cached plan is deallocated, this member used to free jit resources
and
memory.
3. Current problems.
When module is compiled, it needs to connect ExprState and function
addresses.
In old implementation funcname is stored in ExprState.
In cached implementation the fuction will be called second and more
times,
and calling code does not have information about function name for
ExprState.
a) The current cached implementation uses the number of the call to
connect
f.e. 1st expresion and 1st function. It does not work for queries, that
generates an expression after module compilation (f.e. HashJoin) and
tries
to compile it.
b) Also query with aggregate functions generates an expresion every
time, when
executed. It work with current approach, but these expressions should be
considered, as they have different expression address every time.
One of the solution for a) and b) - generate jit-code for Expr pointers
only
in cached plan. Every new created expression either should be ignored by
the compiler and executed by the standard interpreter, or compiled in
the
standard (not cached) jit (it will run compilation every query run and
eliminate all gain from jit-cache).
c) new jit-code generation (use the stuct member instead of the direct
absolute address) slightly decreases the jit-code performance. It is
possible
to compile old version for not cached queries, and new code for cached
queries.
In this case two big 3000 lines funtions llvm_compile_expr() need to be
maintained in similar way, when new expresiions or features are added.
Attached files have
1) the patch (branched from 83ea6c54025bea67bcd4949a6d58d3fc11c3e21b
master),
2 and 3) benchmark files jitinit.sql to create jitbench database and
bash
script jitbench.sh (change to own user and password if you need) to run
banchmark.
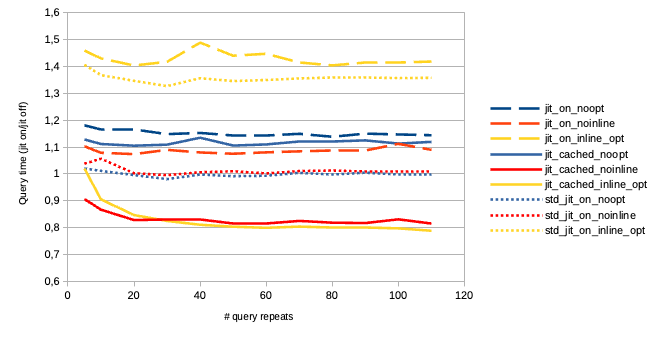
4) chart for this benchmark and the query in the benchmark (comparison
with jit=off as 1 unit). It is easy to find query, where jit is higher
or
lower than jit-off. Here I demonstate the difference of standard and new
jit-code (the decrease of the performance with compilation without
optimization), and high gain of cached version with optimization and
high lost of not cached version with optimization due to the running
of the optimization for every the query.
--
Best regards,
Vladlen Popolitov.
| Attachment | Content-Type | Size |
|---|---|---|
| v4-0001-jit-saved-for-cached-plans.patch | text/x-diff | 142.3 KB |
| jitinit.sql | text/plain | 627 bytes |
| jitbench.sh | text/plain | 3.4 KB |
|
image/png | 29.9 KB |
Responses
- Re: PoC. The saving of the compiled jit-code in the plan cache at 2025-02-13 14:49:38 from Vladlen Popolitov
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Ilia Evdokimov | 2025-02-13 09:05:55 | Re: explain analyze rows=%.0f |
| Previous Message | Anton A. Melnikov | 2025-02-13 07:48:15 | Re: Change GUC hashtable to use simplehash? |