RE: Conflict detection for update_deleted in logical replication
| From: | "Hayato Kuroda (Fujitsu)" <kuroda(dot)hayato(at)fujitsu(dot)com> |
|---|---|
| To: | pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Nisha Moond <nisha(dot)moond412(at)gmail(dot)com>, Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com>, shveta malik <shveta(dot)malik(at)gmail(dot)com>, "Zhijie Hou (Fujitsu)" <houzj(dot)fnst(at)fujitsu(dot)com>, Amit Kapila <amit(dot)kapila16(at)gmail(dot)com> |
| Subject: | RE: Conflict detection for update_deleted in logical replication |
| Date: | 2024-12-11 09:29:51 |
| Message-ID: | TYAPR01MB5692B0182356F041DC9DE3B5F53E2@TYAPR01MB5692.jpnprd01.prod.outlook.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Dear hackers,
I did some benchmarks with the patch. More detail, a pub-sub replication system
was built and TPS was measured on the subscriber. Results were shown that the
performance can be degraded if the wal_receiver_status_interval is long.
This is expected behavior because the patch retains more dead tuples on the
subscriber side.
Also, we've considered a new mechanism which dynamically tunes the period of status
request, and confirmed that it reduced the regression. This is described the latter
part.
Below part contained the detailed report.
## Motivation - why the benchmark is needed
V15 patch set introduces a new replication slot on the subscriber side to retain
needed tuples for the update_deleted detection.
However, this may affect the performance of query executions on the subscriber because
1) tuples to be scaned will be increased and 2) HOT update cannot be worked.
The second issue comes from the fact that HOT update can work only when both tuples
can be located on the same page.
Based on above reasons I ran benchmark tests for the subscriber. The variable of the
measurement is the wal_receiver_status_interval, which controls the duration of status request.
## Used source code
HEAD was 962da900, and applied v15 patch set atop it.
## Environment
RHEL 7 machine which has 755GB memory, 4 physical CPUs and 120 logical processors.
## Workload
1. Constructed a pub-sub replication system.
Parameters for both instances were:
share_buffers = 30GB
min_wal_size = 10GB
max_wal_size = 20GB
autovacuum = false
track_commit_timestamp = on (only for subscriber)
2. Ran pgbench with initialize mode. The scale factor was set to 100.
3. Ran pgbench with 60 clients for the subscriber. The duration was 120s,
and the measurement was repeated 5 times.
Attached script can automate above steps. You can specify the source type in the
measure.sh and run it.
## Comparison
The performance testing was done for HEAD and patched source code.
In case of patched, "detect_update_deleted" parameter was set to on. Also, the
parameter "wal_receiver_status_interval" was varied to 1s, 10s, and 100s to
check the effect.
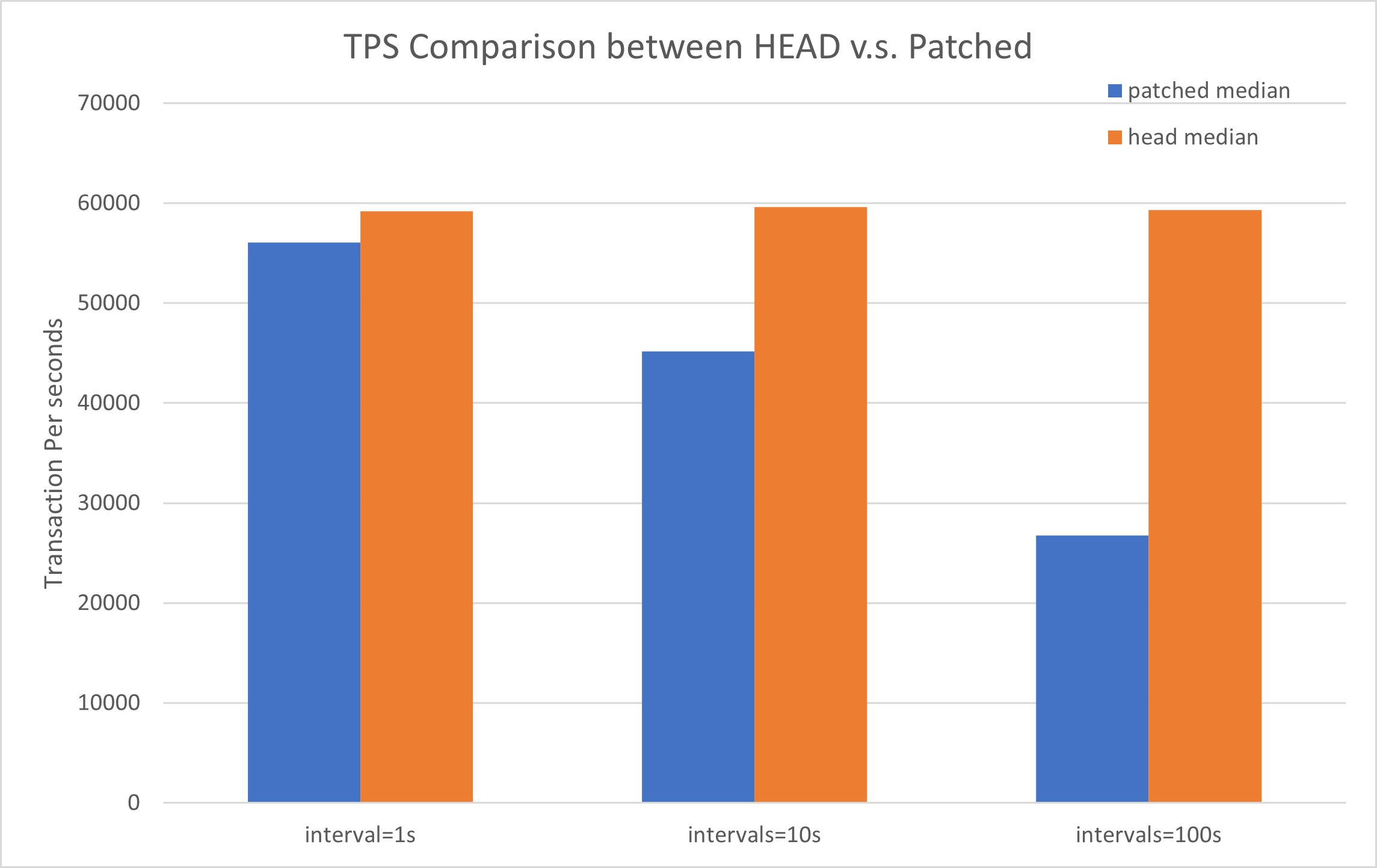
Appendix table shows results [1]. The regression becomes larger based on the wal_receiver_status_interval.
TPS regressions are almost 5%(interval=1s) -> 25%(intervals=10s) -> 55% (intervals=55%).
Attached png file visualize the result: each bar shows median.
## Analysis
I attached to the backend via perf and found that heapam_index_fetch_tuple()
consumed much CPU time ony in case of patched [2]. Also, I checked pg_stat_all_tables
view and found that HOT update rarely happened only in the patched case [3].
This means that whether backend could do HOT update is the dominant.
When the detect_update_deleted = on, the additional slot is defined on the subscriber
ide and it is updated based on the activity; The frequency is determined by the
wal_receiver_status_intervals. In intervals=100s case, it is relatively larger
for the workload so that some dead tuples remained, this makes query processing slower.
This result means that users may have to tune consider the interval period based
on their workload. However, it is difficult to predict the appropriate value.
## Experiment - dynamic period tuning
Based on above, I and Hou discussed off-list and implemented new mechanism which
tunes the duration between status request dynamically. The basic idea is similar
with what slotsync worker does. The interval of requests is initially 100ms,
and becomes twice when if there are no XID assignment since the last advancement.
The maxium value is either of wal_receiver_status_interval or 3min.
Benchmark results with this are shown in [4]. Here wal_receiver_status_interval
is not changed, so we can compare with the HEAD and interval=10s case in [1] - 59536 vs 59597.
The regression is less than 1%.
The idea has already been included in v16-0002, please refer it.
## Experiment - shorter interval
Just in case - I did an extreme case that wal_receiver_status_interval is quite short - 10ms.
To make interval shorter I implemented an attached patch for both cases. Results are shown [5].
The regression is not observed or even better (I think this is caused by the randomness).
This experiment also shows the result that the regression is happened due to the dead tuple.
## Appendix [1] - result table
Each cells show transaction per seconds of the run.
patched
# run interval=1s intervals=10s intervals=100s
1 55876 45288 26956
2 56086 45336 26799
3 56121 45129 26753
4 56310 45169 26542
5 55389 45071 26735
median 56086 45169 26753
HEAD
# run interval=1s intervals=10s intervals=100s
1 59096 59343 59341
2 59671 59413 59281
3 59131 59597 58966
4 59239 59693 59518
5 59165 59631 59487
median 59165 59597 59341
## Appendix [2] - perf analysis
patched:
```
- 58.29% heapam_index_fetch_tuple
+ 38.28% heap_hot_search_buffer
+ 13.88% ReleaseAndReadBuffer
5.34% heap_page_prune_opt
+ 13.88% ReleaseAndReadBuffer
```
head:
```
- 2.13% heapam_index_fetch_tuple
1.06% heap_hot_search_buffer
0.62% heap_page_prune_opt
```
## Appendix [3] - pg_stat
patched
```
postgres=# SELECT relname, n_tup_upd, n_tup_hot_upd, n_tup_newpage_upd, n_tup_upd - n_tup_hot_upd AS n_tup_non_hot FROM pg_stat_all_tables where relname like 'pgbench%';
relname | n_tup_upd | n_tup_hot_upd | n_tup_newpage_upd | n_tup_non_hot
------------------+-----------+---------------+-------------------+---------------
pgbench_history | 0 | 0 | 0 | 0
pgbench_tellers | 453161 | 37996 | 415165 | 415165
pgbench_accounts | 453161 | 0 | 453161 | 453161
pgbench_branches | 453161 | 272853 | 180308 | 180308
(4 rows)
```
head
```
postgres=# SELECT relname, n_tup_upd, n_tup_hot_upd, n_tup_newpage_upd, n_tup_upd - n_tup_hot_upd AS n_tup_non_hot FROM
pg_stat_all_tables where relname like 'pgbench%';
relname | n_tup_upd | n_tup_hot_upd | n_tup_newpage_upd | n_tup_non_hot
------------------+-----------+---------------+-------------------+---------------
pgbench_history | 0 | 0 | 0 | 0
pgbench_tellers | 2078197 | 2077583 | 614 | 614
pgbench_accounts | 2078197 | 1911535 | 166662 | 166662
pgbench_branches | 2078197 | 2078197 | 0 | 0
(4 rows)
```
## Appendix [4] - dynamic status request
# run dynamic (v15 + PoC)
1 59627
2 59536
3 59359
4 59443
5 59541
median 59536
## Apendix [5] - shorter wal_receiver_status_interval
pached
# run interval=10ms
1 58081
2 57876
3 58083
4 57915
5 57933
median 57933
head
# run interval=10ms
1 57595
2 57322
3 57271
4 57421
5 57590
median 57421
Best regards,
Hayato Kuroda
FUJITSU LIMITED
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 42.3 KB |
| change_to_ms.diffs | application/octet-stream | 5.0 KB |
| measure.sh | application/octet-stream | 729 bytes |
| setup.sh | application/octet-stream | 1.3 KB |
In response to
- RE: Conflict detection for update_deleted in logical replication at 2024-12-11 09:02:19 from Zhijie Hou (Fujitsu)
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David Rowley | 2024-12-11 09:38:14 | Re: Proposals for EXPLAIN: rename ANALYZE to EXECUTE and extend VERBOSE |
| Previous Message | vignesh C | 2024-12-11 09:11:27 | Re: Memory leak in pg_logical_slot_{get,peek}_changes |