| From: | Akshay Joshi <akshay(dot)joshi(at)enterprisedb(dot)com> |
|---|---|
| To: | pgadmin-hackers <pgadmin-hackers(at)postgresql(dot)org> |
| Cc: | Dave Page <dpage(at)pgadmin(dot)org>, Shirley Wang <swang(at)pivotal(dot)io>, Robert Eckhardt <reckhardt(at)pivotal(dot)io> |
| Subject: | Re: Declarative partitioning in pgAdmin4 |
| Date: | 2017-06-13 13:59:33 |
| Message-ID: | CANxoLDeC9e+=ESBzoCSQeg4zgxwTz5zGG8HwYs9JNr90x4a-tA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgadmin-hackers |
Hi All
For further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created
below partitioned table
CREATE TABLE public.sales
(
country character varying COLLATE pg_catalog."default" NOT NULL,
sales bigint,
saledate date
) PARTITION BY RANGE (*country, date_part('year'::text, sale date)*)
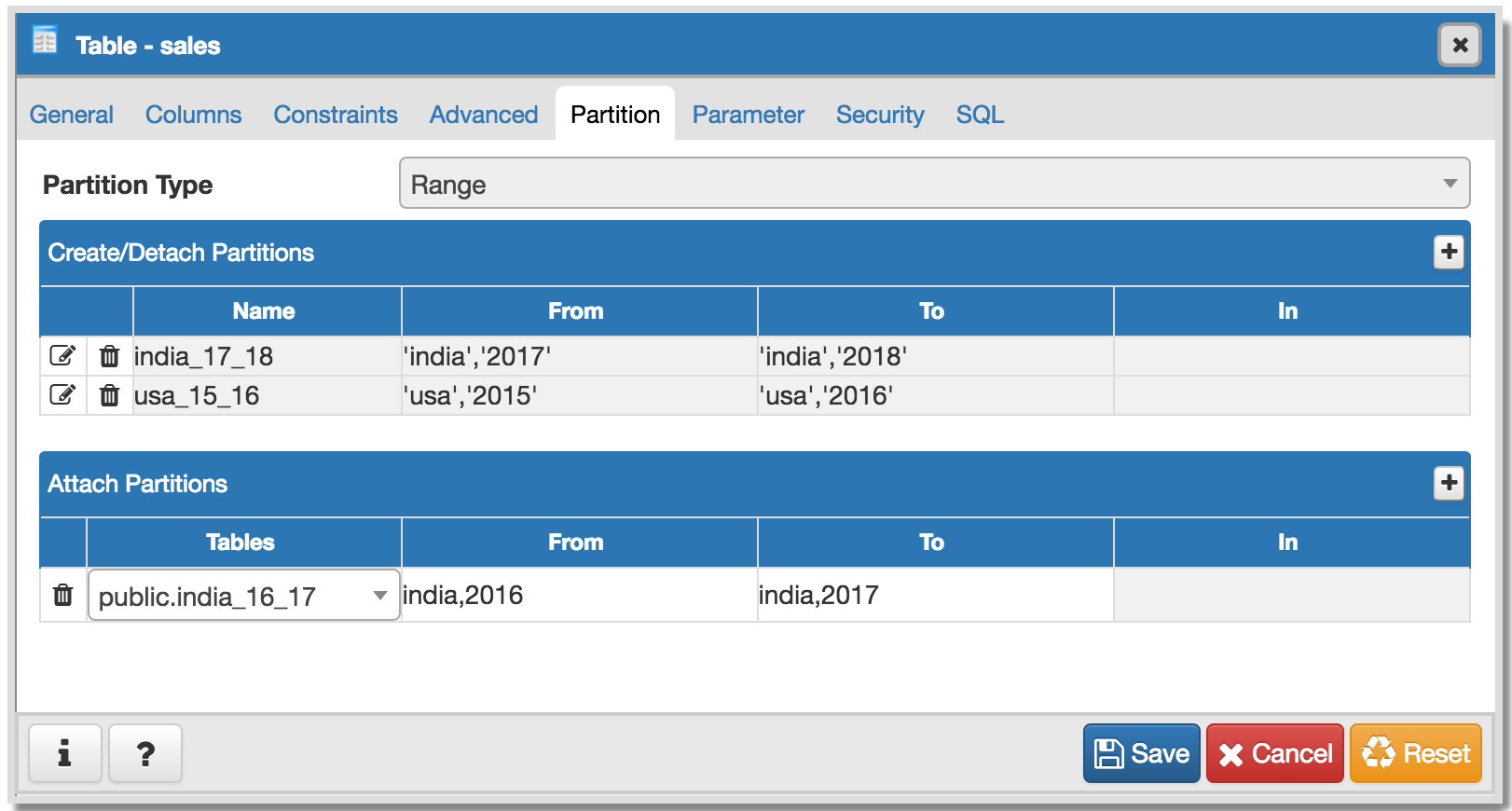
When user open the properties dialog I am not able to figure out how to
parse keys(displayed in bold in above example) and show them in our control
that we used. For the time being I have hide that control in 'Edit' mode
(Refer Attach Partition.png)
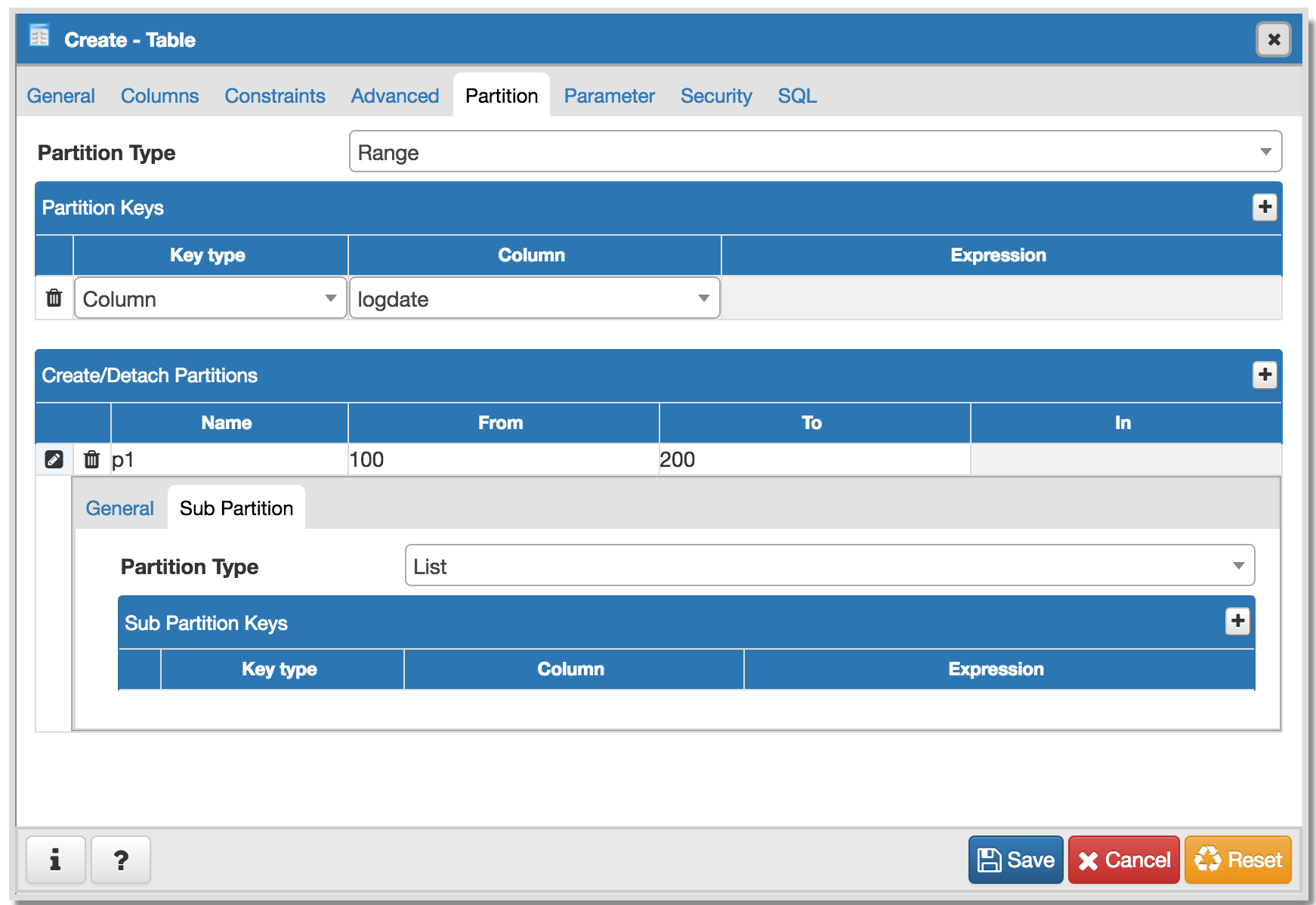
- *Support of sub partitioning*: To implement sub-partitioning, specify
the PARTITION BY clause in the commands used to create individual
partitions, for example:
-
CREATE TABLE measurement_y2006 PARTITION OF measurement
FOR VALUES FROM ('2006-02-01') TO ('2006-03-01')
PARTITION BY RANGE (peaktemp);
To achieve above I have made some changes in GUI (Refer Sub
Partition.png).
*Complex and challenging part here is "measurement_y2006" is
partition of "measurement" and parent table for other partitions too which
user can create later. How we will going to show this in browser tree? *
One option could be
Tables
->measurement(table)
->Partitions
->measurement_y2006(Partition of measurement and parent of
p1)
->Partitions
->p1
- *Attach Partitions*: To implement attach N partitions I have made some
changes in GUI( Refer Attach Partition.png). Attach Partitions control
will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be
done to complete that.
Please review the design. Suggestions/Comments are welcome.
On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt(at)pivotal(dot)io>
wrote:
>
>
> On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage(at)pgadmin(dot)org> wrote:
>
>>
>> For roll up this pattern seems obvious, identify the n partitions you
>>> need/want to combine and then run a job to combine them.
>>>
>>
>> You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless
>> you're thinking we should create such a feature in pgAdmin.
>>
>> Of course, I have no objection to extending what we do in PG to add GP
>> feature support, but let's start with PG.
>>
>
> No not at all. That was a very specific and consistent pattern described
> by users leveraging time based range partitions in Postgres. I'm not sure
> if that same use case will be supported with partitioning as implemented in
> Postgres 10 but it is a Postgres pattern.
>
> -- Rob
>
>
>>
>>
>>>
>>> For other patterns such as creating indexes and such it requires a bit
>>> more thought. Generally users described wanting to treat all of the
>>> children like a single table (just like Oracle), however, other users
>>> described potentially modifying chunks of partitions differently depending
>>> on some criterion. This means that users will need to identify the subset
>>> they want to optimize and then ideally be able to act on them all at once.
>>>
>>
>> Right.
>>
>>
>>>
>>> -- Rob
>>>
>>>
>>>
>>>
>>>
>>>
>>>>
>>>> So... it sounds like we're on the right lines :-)
>>>>
>>>>
>>>>>
>>>>> For the former, this can be addressed by enabling users to modify one
>>>>> or more child partitions at the same time. For the latter, that is a
>>>>> workflow that might be addressed outside of the create table with partition
>>>>> workflow we're working on currently.
>>>>>
>>>>>
>>>>>
>>>>>
>>>>>
>>>>> On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage(at)pgadmin(dot)org> wrote:
>>>>>
>>>>>> On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <
>>>>>> akshay(dot)joshi(at)enterprisedb(dot)com> wrote:
>>>>>>
>>>>>>> Hi All
>>>>>>>
>>>>>>> Following are the further implementation updates to support
>>>>>>> Declarative Partitioning:
>>>>>>>
>>>>>>> - Show all the existing partitions of the parent table in
>>>>>>> Partitions tab (Refer Existing_Partitions.png)
>>>>>>> - Ability to create N partitions and detach existing partitions.
>>>>>>> Refer (Create_Detach_Partition.png), in this example I have
>>>>>>> detach two existing partition and create two new partitions.
>>>>>>> - Added "Detach Partition" menu to partitions node only and user
>>>>>>> will be able to detach from there as well. Refer (Detach.png)
>>>>>>>
>>>>>>> That's looking good to me :-)
>>>>>>
>>>>>>
>>>>>>
>>>>>>>
>>>>>>>
>>>>>>> On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <
>>>>>>> reckhardt(at)pivotal(dot)io> wrote:
>>>>>>>
>>>>>>>>
>>>>>>>>
>>>>>>>> On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <
>>>>>>>> akshay(dot)joshi(at)enterprisedb(dot)com> wrote:
>>>>>>>>
>>>>>>>>>
>>>>>>>>> Taking average of two columns is just an example/representation
>>>>>>>>> of expression, there is no use case of that. As I am also in learning
>>>>>>>>> phase. Below are some use case that I can think of:
>>>>>>>>>
>>>>>>>>> -
>>>>>>>>>
>>>>>>>>> Partitions based on first letter of their username
>>>>>>>>>
>>>>>>>>> CREATE TABLE users (
>>>>>>>>> id serial not null,
>>>>>>>>> username text not null,
>>>>>>>>> password text,
>>>>>>>>> created_on timestamptz not null,
>>>>>>>>> last_logged_on timestamptz not null
>>>>>>>>> )PARTITION BY RANGE ( lower( left( username, 1 ) ) );
>>>>>>>>> CREATE TABLE users_0
>>>>>>>>> partition of users (id, primary key (id), unique (username))
>>>>>>>>> for values from ('a') to ('g');
>>>>>>>>> CREATE TABLE users_1
>>>>>>>>> partition of users (id, primary key (id), unique (username))
>>>>>>>>> for values from ('g') to (unbounded);
>>>>>>>>>
>>>>>>>>> - Partition based on country's sale for each month of an year.
>>>>>>>>>
>>>>>>>>> CREATE TABLE public.sales
>>>>>>>>>
>>>>>>>>> (
>>>>>>>>>
>>>>>>>>> country text NOT NULL,
>>>>>>>>>
>>>>>>>>> sales bigint NOT NULL,
>>>>>>>>>
>>>>>>>>> saledate date
>>>>>>>>>
>>>>>>>>> ) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)),
>>>>>>>>> (extract(MONTH FROM saledate)))
>>>>>>>>>
>>>>>>>>>
>>>>>>>>> CREATE TABLE public.sale_usa_2017_jan PARTITION OF sales
>>>>>>>>>
>>>>>>>>> FOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);
>>>>>>>>>
>>>>>>>>> CREATE TABLE public.sale_india_2017_jan PARTITION OF sales
>>>>>>>>>
>>>>>>>>> FOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);
>>>>>>>>>
>>>>>>>>> CREATE TABLE public.sale_uk_2017_jan PARTITION OF sales
>>>>>>>>>
>>>>>>>>> FOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);
>>>>>>>>>
>>>>>>>>>
>>>>>>>>> INSERT INTO sales VALUES ('india', 10000, '2017-1-15');
>>>>>>>>>
>>>>>>>>> INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');
>>>>>>>>>
>>>>>>>>> INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');
>>>>>>>>>
>>>>>>>>> Apart from above there may be N number of use cases that
>>>>>>>>> depends on specific requirement of user.
>>>>>>>>>
>>>>>>>>
>>>>>>>> Thank you for the example, you are absolutely correct and we were
>>>>>>>> confused.
>>>>>>>>
>>>>>>>> Given our new found understanding do you mind if we iterate a bit
>>>>>>>> on the UI/UX? What we were suggesting with the daily/monthly/yearly drop
>>>>>>>> down was a specific example of an expression. Given that fact that doesn't
>>>>>>>> seem to be required in an MVP, however, I do think a more interactive
>>>>>>>> experience between the definition of the child partitions and the creation
>>>>>>>> of the partitions would be optimal.
>>>>>>>>
>>>>>>>> I'm not sure where you are with respect to implementing the UI but
>>>>>>>> I'd love to float some ideas and mock ups past you.
>>>>>>>>
>>>>>>>> -- Rob
>>>>>>>>
>>>>>>>
>>>>>>>
>>>>>>>
>>>>>>> --
>>>>>>> *Akshay Joshi*
>>>>>>> *Principal Software Engineer *
>>>>>>>
>>>>>>>
>>>>>>>
>>>>>>> *Phone: +91 20-3058-9517 <+91%2020%203058%209517>Mobile: +91
>>>>>>> 976-788-8246 <+91%2097678%2088246>*
>>>>>>>
>>>>>>>
>>>>>>> --
>>>>>>> Sent via pgadmin-hackers mailing list (pgadmin-hackers(at)postgresql(dot)or
>>>>>>> g)
>>>>>>> To make changes to your subscription:
>>>>>>> http://www.postgresql.org/mailpref/pgadmin-hackers
>>>>>>>
>>>>>>>
>>>>>>
>>>>>>
>>>>>> --
>>>>>> Dave Page
>>>>>>
>>>>>> Blog: http://pgsnake.blogspot.com
>>>>>> Twitter: @pgsnake
>>>>>>
>>>>>> EnterpriseDB UK: http://www.enterprisedb.com
>>>>>> The Enterprise PostgreSQL Company
>>>>>>
>>>>>
>>>>
>>>>
>>>> --
>>>> Dave Page
>>>> Blog: http://pgsnake.blogspot.com
>>>> Twitter: @pgsnake
>>>>
>>>> EnterpriseDB UK: http://www.enterprisedb.com
>>>> The Enterprise PostgreSQL Company
>>>>
>>>
>>>
>>
>>
>> --
>> Dave Page
>> Blog: http://pgsnake.blogspot.com
>> Twitter: @pgsnake
>>
>> EnterpriseDB UK: http://www.enterprisedb.com
>> The Enterprise PostgreSQL Company
>>
>
>
--
*Akshay Joshi*
*Principal Software Engineer *
*Phone: +91 20-3058-9517Mobile: +91 976-788-8246*
| Attachment | Content-Type | Size |
|---|---|---|
| Attach Partition.png | image/png | 115.4 KB |
| Sub Partition.png | image/png | 138.7 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | pgAdmin 4 Jenkins | 2017-06-13 14:01:39 | Jenkins build is back to normal : pgadmin4-master-python27 #174 |
| Previous Message | pgAdmin 4 Jenkins | 2017-06-13 13:53:58 | Jenkins build is back to normal : pgadmin4-master-python35 #167 |
{kind=link}
{kind=link}