Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-01-06 13:36:00 |
| Message-ID: | CANtu0ojHAputNCH73TEYN_RUtjLGYsEyW1aSXmsXyvwf=3U4qQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello, everyone!
Some benchmark results are ready. You can access them via [0] or check the
attachments. The benchmark code is available at [1].
A few words about the environments and tests:
There are two environments:
* local: AMD Ryzen 7 7700X (8-Core), 32GB RAM, local high-performance NVMe
SSD [2].
* io2: AWS t2.2xlarge, 8 vCPUs, 32GB RAM, 300GB io2 with 64,000 IOPS (the
fastest available).
There are few tests:
* btree_abalance - A basic new index on a frequently modified field
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts (abalance)
* btree_unique - A simple unique index
query: CREATE UNIQUE INDEX CONCURRENTLY idx ON pgbench_accounts (aid)
* btree_unique_hot - A unique index with multiple tuples sharing the same
value, caused by another index
schema: CREATE INDEX idx2 ON pgbench_accounts (abalance)
query: CREATE UNIQUE INDEX CONCURRENTLY idx ON pgbench_accounts (aid)
* brin - A basic BRIN index
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts USING
brin(abalance)
* hash - A basic hash index
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts USING hash(bid)
* gist - A simple GiST index
schema: CREATE EXTENSION btree_gist
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts using
gist(abalance)
* gin - A simple GIN index
schema: CREATE EXTENSION btree_gin
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts using
gin(abalance)
The tests were executed on the pgbench schema with a scale factor of 2000
(approximately 30GB) and a fill factor of 95.
Two types of concurrent loads were tested:
* IO-bound scenario: pgbench with 8 clients.
* CPU-bound scenario: pgbench with 50 clients.
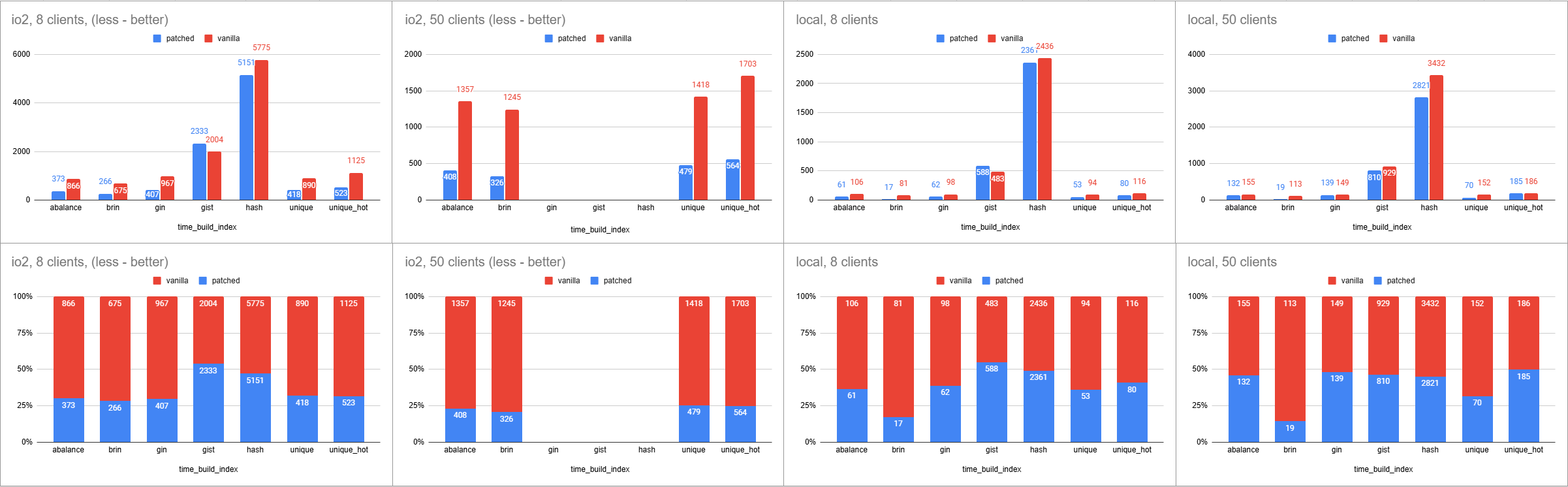
As you can see, the index build time results are quite impressive—up to 4x
faster in some cases!
However, there’s something unusual with the GiST index. Occasionally,
sometimes it takes more time to build. I'll investigate that.
The auxiliary index size is relatively small, typically less than 1MB.
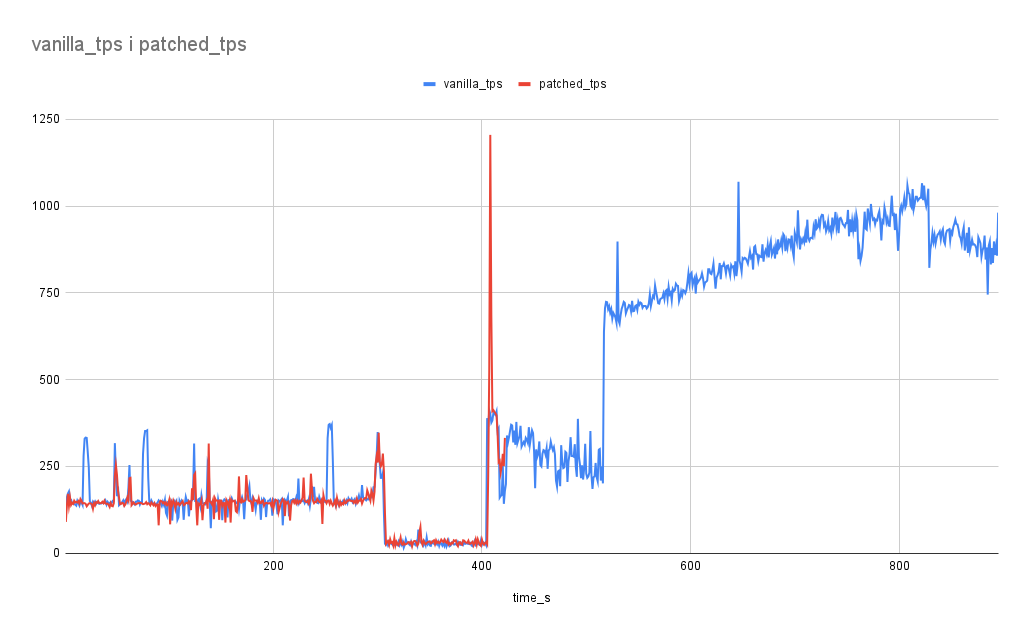
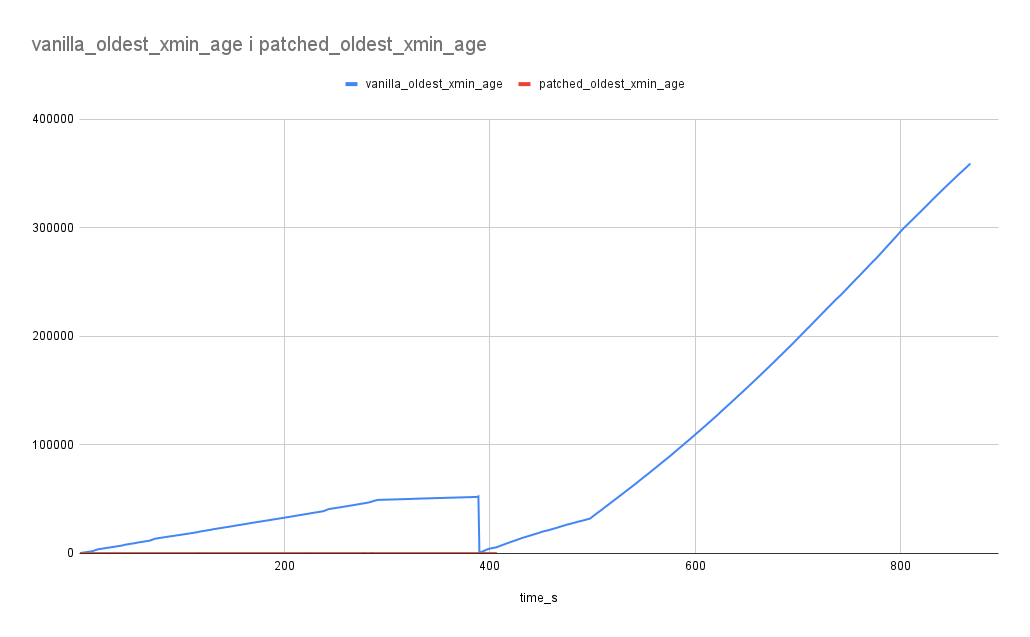
You can also observe the typical comparison results of TPS and oldest xmin
during index builds in the provided images (except for GiST, which shows
some anomalies).
>> (mostly because of a single heap scan).
> Isn't there a second heap scan, or do you consider that an index scan?
It is something between.
First phase: a regular heap scan is performed (with snapshot resetting).
Second phase: we collect all TIDs from target and auxiliary indexes, sort
them, and fetch from heap only records which are not present in the target
index (new tuples created during the first phase).
> I think a good benchmark could show how bloat is actually prevented,
> i.e. through result table size comparisons on an update-heavy
> workload, both with and without the patch.
> I think it shouldn't be too difficult to show how such workloads
> quickly regress to always extending the table as no cleanup can
> happen, while patched they'd have much more leeway due to page
> pruning. Presumably a table with a fillfactor <100 would show the best
> results.
I can’t see any significant differences from these tests so far. However, I
think this might be due to the random selection of tuples—there’s almost
always space available to place a new version on the same page.
I’ll try running the tests with a different distribution. Additionally, to
produce bloat comparable to a ~30GB table, updates will need to run for a
longer period.
Best regards,
Mikhail.
[0]:
https://docs.google.com/spreadsheets/d/1UYaqpsWSfYdZdQxaqY4gVo0RW6KrT0d-U1VDNJB8lVk/edit?usp=sharing
[1]:
https://gist.github.com/michail-nikolaev/b33fb0ac1f35729388c89f72db234b0f
[2]:
https://www.harddrivebenchmark.net/hdd.php?hdd=WD%20PC%20SN810%20SDCPNRZ%202TB&id=29324
| Attachment | Content-Type | Size |
|---|---|---|
| PG benchmark 2 - summary.pdf | application/pdf | 417.4 KB |
|
image/png | 68.8 KB |
| graphs.png | image/png | 108.8 KB |
|
image/png | 26.0 KB |
{kind=link}
In response to
- Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements at 2025-01-04 01:12:58 from Matthias van de Meent
Responses
- Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements at 2025-01-08 02:12:00 from Michail Nikolaev
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Robert Haas | 2025-01-06 14:20:18 | Re: Fwd: Re: A new look at old NFS readdir() problems? |
| Previous Message | Aleksander Alekseev | 2025-01-06 13:23:33 | Re: [PATCH] Refactor SLRU to always use long file names |