Re: Improve CRC32C performance on SSE4.2
| From: | John Naylor <johncnaylorls(at)gmail(dot)com> |
|---|---|
| To: | "Devulapalli, Raghuveer" <raghuveer(dot)devulapalli(at)intel(dot)com> |
| Cc: | "pgsql-hackers(at)lists(dot)postgresql(dot)org" <pgsql-hackers(at)lists(dot)postgresql(dot)org>, "Shankaran, Akash" <akash(dot)shankaran(at)intel(dot)com> |
| Subject: | Re: Improve CRC32C performance on SSE4.2 |
| Date: | 2025-02-09 09:00:24 |
| Message-ID: | CANWCAZahvhE-+htZiUyzPiS5e45ukx5877mD-dHr-KSX6LcdjQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Thu, Feb 6, 2025 at 3:49 AM Devulapalli, Raghuveer
<raghuveer(dot)devulapalli(at)intel(dot)com> wrote:
>
> This patch improves the performance of SSE42 CRC32C algorithm. The current SSE4.2 implementation of CRC32C relies on the native crc32 instruction and processes 8 bytes at a time in a loop. The technique in this paper uses the pclmulqdq instruction and processing 64 bytes at time. The algorithm is based on sse42 version of crc32 computation from Chromium’s copy of zlib with modified constants for crc32c computation. See:
>
>
>
> https://chromium.googlesource.com/chromium/src/+/refs/heads/main/third_party/zlib/crc32_simd.c
Thanks for the patch!
> Microbenchmarks (generated with google benchmark using a standalone version of the same algorithms):
|----------------------------------+---------------------+---------------+---------------|
| Benchmark | Buffer size (bytes) | Time Old
(ns) | Time New (ns) |
|----------------------------------+---------------------+---------------+---------------|
| [scalar_crc32c vs. sse42_crc32c] | 64 | 33
| 6 |
| [scalar_crc32c vs. sse42_crc32c] | 128 | 88
| 9 |
| [scalar_crc32c vs. sse42_crc32c] | 256 | 211
| 17 |
| [scalar_crc32c vs. sse42_crc32c] | 512 | 486
| 30 |
| [scalar_crc32c vs. sse42_crc32c] | 1024 | 1037
| 57 |
| [scalar_crc32c vs. sse42_crc32c] | 2048 | 2140
| 116 |
|----------------------------------+---------------------+---------------+---------------|
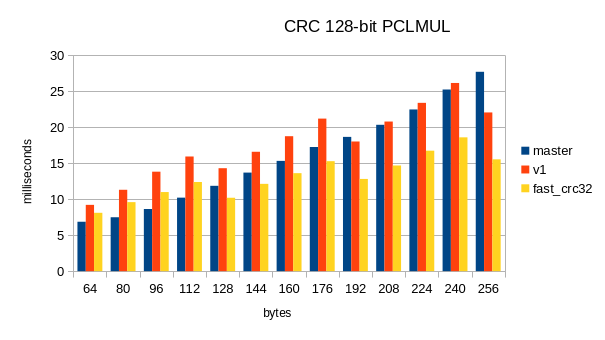
I'm highly suspicious of these numbers because they show this version
is about 20x faster than "scalar", so relatively speaking 3x faster
than the AVX-512 proposal? I ran my own benchmarks with the attached
script using your test function from the other thread, and found this
patch is actually slower than master on anything smaller than 256
bytes. Luckily, that's easily fixable: It turns out the implementation
in the paper (and chromium) has a very inefficient finalization step,
using more carryless multiplications and plenty of other operations.
After the main loop, and at the end, it's much more efficient to
convert the 128-bit intermediate result directly into a CRC in the
usual way. See here for details:
https://www.corsix.org/content/alternative-exposition-crc32_4k_pclmulqdq
The author of this article also has an MIT-licensed program to
generate CRC implementations with specified requirements (including on
ARM):
https://github.com/corsix/fast-crc32
I generated a similar function for v2-0004 and this benchmark shows
it's faster than master on 128 bytes and above, which is encouraging
(see attached graph). As I mentioned in the other thread, we need to
be mindful of the fact that the latency of carryless multiplication
varies wildly on different microarchitectures. I did the benchmarks on
my older machine, which I believe has a latency of 7 cycles for this
instruction. Looking around *briefly*, the most recent x86 chips with
worse latency seem to be from around 2012-13 (e.g. Intel Silvermont
and AMD Piledriver). Chips newer than mine have a latency of 4-7
cycles. It seems okay to assume those who care the most about
performance will be on hardware less than 12 years old, but I'm open
to arguments to be more conservative here.
Large inputs would make the graph hard to read, so I'll just put the
results for 8kB here:
master: 1504ms
v1: 543ms
v2: 533ms
Some thoughts on building (not a complete review):
--- a/config/c-compiler.m4
+++ b/config/c-compiler.m4
@@ -557,14 +557,19 @@ AC_DEFUN([PGAC_SSE42_CRC32_INTRINSICS],
[define([Ac_cachevar], [AS_TR_SH([pgac_cv_sse42_crc32_intrinsics])])dnl
AC_CACHE_CHECK([for _mm_crc32_u8 and _mm_crc32_u32], [Ac_cachevar],
[AC_LINK_IFELSE([AC_LANG_PROGRAM([#include <nmmintrin.h>
+ #include <wmmintrin.h>
#if defined(__has_attribute) && __has_attribute (target)
- __attribute__((target("sse4.2")))
+ __attribute__((target("sse4.2,pclmul")))
It's probably okay to fold these together in the same compile-time
check, since both are fairly old by now, but for those following
along, pclmul is not in SSE 4.2 and is a bit newer. So this would
cause machines building on Nehalem (2008) to fail the check and go
back to slicing-by-8 with it written this way. That's a long time ago,
so I'm not sure if anyone would notice, and I think we could fix it
for people using a packaged binary by having a fallback wrapper
function that just calls the SSE 4.2 "tail", as 0002 calls it.
--
John Naylor
Amazon Web Services
| Attachment | Content-Type | Size |
|---|---|---|
| test-crc.sh | application/x-shellscript | 259 bytes |
|
image/png | 19.1 KB |
| v2-0002-Add-a-Postgres-SQL-function-for-crc32c-benchmarki.patch | text/x-patch | 6.4 KB |
| v2-0003-Improve-CRC32C-performance-on-SSE4.2.patch | text/x-patch | 9.8 KB |
| v2-0001-Add-more-test-coverage-for-crc32c.patch | text/x-patch | 3.4 KB |
| v2-0004-Shorter-version-from-corsix.patch | text/x-patch | 7.7 KB |
In response to
- Improve CRC32C performance on SSE4.2 at 2025-02-05 20:48:56 from Devulapalli, Raghuveer
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Pavel Luzanov | 2025-02-09 09:11:04 | Re: Things I don't like about \du's "Attributes" column |
| Previous Message | Alexander Lakhin | 2025-02-09 08:00:00 | Re: Virtual generated columns |