| From: | Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com> |
|---|---|
| To: | Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Re: Make pg_stat_io view count IOs as bytes instead of blocks |
| Date: | 2024-12-04 11:29:00 |
| Message-ID: | CAN55FZ10jKqGm0GwnxOxCrSLoNW2SYP_ZcorvSPS808-Gx2_Gw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
Thanks for looking into this!
On Wed, 27 Nov 2024 at 19:08, Melanie Plageman
<melanieplageman(at)gmail(dot)com> wrote:
>
> On Wed, Sep 11, 2024 at 7:19 AM Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com> wrote:
> >
> > Currently, in the pg_stat_io view, IOs are counted as blocks. However, there are two issues with this approach:
> >
> > 1- The actual number of IO requests to the kernel is lower because IO requests can be merged before sending the final request. Additionally, it appears that all IOs are counted in block size.
>
> I think this is a great idea. It will allow people to tune
> io_combine_limit as you mention below.
>
> > 2- Some IOs may not align with block size. For example, WAL read IOs are done in variable bytes and it is not possible to correctly show these IOs in the pg_stat_io view [1].
>
> Yep, this makes a lot of sense as a solution.
>
> > To address this, I propose showing the total number of IO requests to the kernel (as smgr function calls) and the total number of bytes in the IO. To implement this change, the op_bytes column will be removed from the pg_stat_io view. Instead, the [reads | writes | extends] columns will track the total number of IO requests, and newly added [read | write | extend]_bytes columns will track the total number of bytes in the IO.
>
> smgr API seems like the right place for this.
>
> > Example benefit of this change:
> >
> > Running query [2], the result is:
> >
> > ╔═══════════════════╦══════════╦══════════╦═══════════════╗
> > ║ backend_type ║ object ║ context ║ avg_io_blocks ║
> > ╠═══════════════════╬══════════╬══════════╬═══════════════╣
> > ║ client backend ║ relation ║ bulkread ║ 15.99 ║
> > ╠═══════════════════╬══════════╬══════════╬═══════════════╣
> > ║ background worker ║ relation ║ bulkread ║ 15.99 ║
> > ╚═══════════════════╩══════════╩══════════╩═══════════════╝
>
> I don't understand why background worker is listed here.
Parallel sequential scan happens in this example and parallel workers
are listed as background workers. After setting
'max_parallel_workers_per_gather' to 0, it is gone.
> > You can rerun the same query [2] after setting io_combine_limit to 32 [3]. The result is:
> >
> > ╔═══════════════════╦══════════╦══════════╦═══════════════╗
> > ║ backend_type ║ object ║ context ║ avg_io_blocks ║
> > ╠═══════════════════╬══════════╬══════════╬═══════════════╣
> > ║ client backend ║ relation ║ bulkread ║ 31.70 ║
> > ╠═══════════════════╬══════════╬══════════╬═══════════════╣
> > ║ background worker ║ relation ║ bulkread ║ 31.60 ║
> > ╚═══════════════════╩══════════╩══════════╩═══════════════╝
> >
> > I believe that having visibility into avg_io_[bytes | blocks] is valuable information that could help optimize Postgres.
>
> In general, for this example, I think it would be more clear if you
> compared what visibility we have in pg_stat_io on master with what
> visibility we have with your patch.
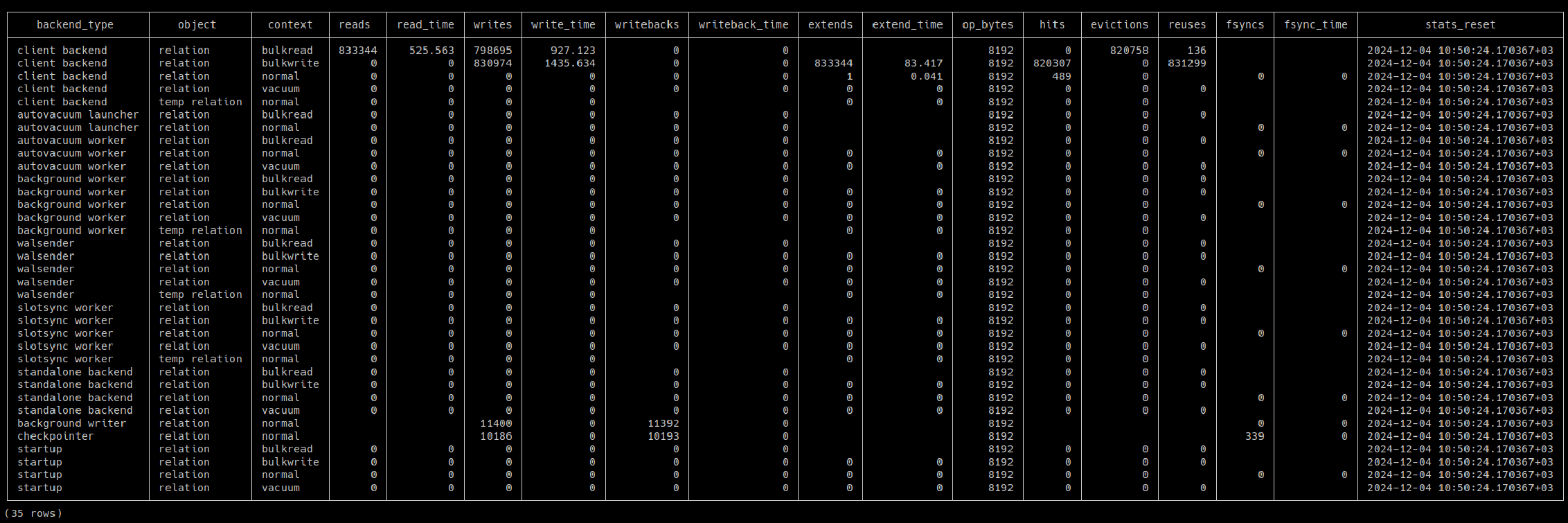
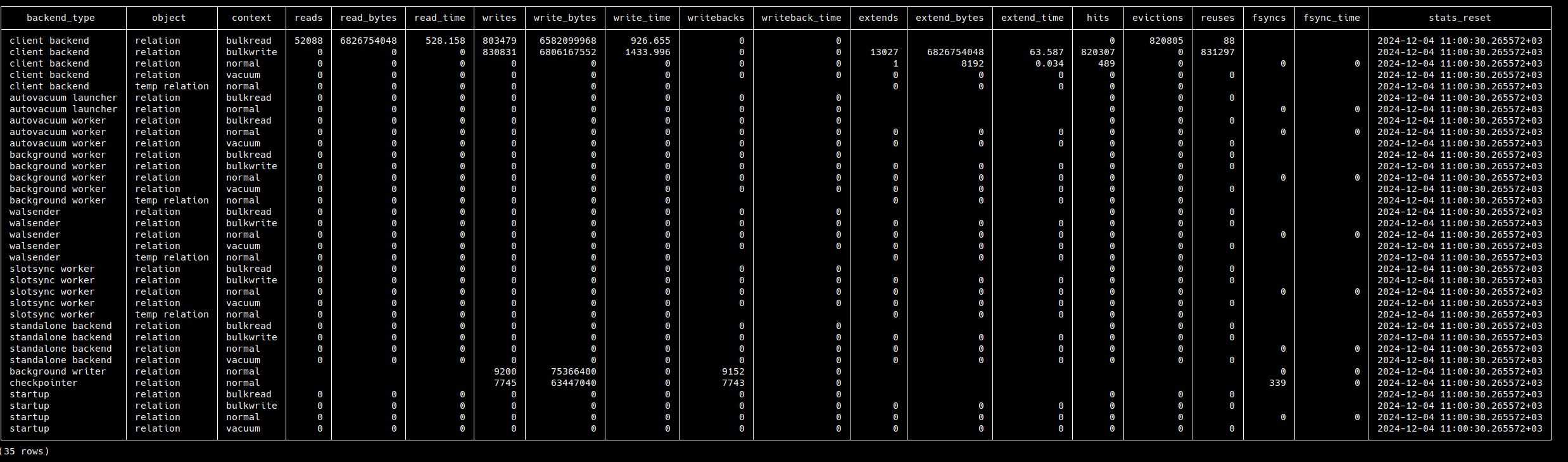
I am listing the changes as text, images are also attached.
* [reads | writes | extends] columns count the number of smgr function
calls now. They were counting the number of block IOs before.
* op_bytes column is removed from the view because each IO could have
a different size. They are not always equal to op_bytes.
* [read_bytes | write_bytes | extend_bytes] columns are added. These
columns count IO sizes as bytes.
There are two different IO cases:
1- Size of the IOs are constant:
* See 'client backend / bulkread' row, If you divide read_bytes
columns' value (6826754048) to BLCKSZ (8192) in the patched image, you
get the reads columns' value (833344) in the upstream image. So, we
actually do not lose any information when the size of the IOs are
constant.
2- Size of the IOs are different:
* Upstream version will give wrong information in this case. For
example see WALRead() function. pg_pread() is called with different
segbytes values in this function. It is not possible to correctly show
this stat in pg_stat_io view.
The problem with the upstream version of the pg_stat_io view is that
multiplying the number of blocks with the op_bytes does not always
give the total IO size. Also, it looks like Postgres is doing one IO
request per block. This patch tries to address these problems.
> I like that you show how io_combine_limit can be tuned using this, but
> I don't think the problem statement is clear nor is the full
> narrative.
I just wanted to show one piece of information that can be gathered
with the patched version, it was not possible to gather that before.
> > CREATE TABLE t as select i, repeat('a', 600) as filler from generate_series(1, 10000000) as i;
> > SELECT pg_stat_reset_shared('io');
> > SELECT * FROM t WHERE i = 0;
> > SELECT backend_type, object, context, TRUNC((read_bytes / reads / (SELECT current_setting('block_size')::numeric)), 2) as avg_io_blocks FROM pg_stat_io WHERE reads > 0;
>
> I like that you calculate the avg_io_blocks, but I think it is good to
> show the raw columns as well.
Images of the view after running the query [1] are attached.
P.S. I attached the images of the view because I do not know how they
will look if I copy paste them as text. If there is a way to add them
as text without distortion, please let me know.
[1]
SET track_io_timing to ON;
SET max_parallel_workers_per_gather TO 0;
SELECT pg_stat_reset_shared('io');
CREATE TABLE t as select i, repeat('a', 600) as filler from
generate_series(1, 10000000) as i;
SELECT * FROM t WHERE i = 0;
SELECT * FROM pg_stat_io;
--
Regards,
Nazir Bilal Yavuz
Microsoft
| Attachment | Content-Type | Size |
|---|---|---|
| upstream_pg_stat_io.png | image/png | 225.3 KB |
| patched_pg_stat_io.png | image/png | 194.4 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Michael Paquier | 2024-12-04 11:38:58 | Re: Memory leak in WAL sender with pgoutput (v10~) |
| Previous Message | Yugo NAGATA | 2024-12-04 11:20:57 | Re: psql: Add leakproof field to \dAo+ meta-command results |
{kind=link}
{kind=link}