problema de desempeño con join basado en funcion similaridad
| From: | Hellmuth Vargas <hivs77(at)gmail(dot)com> |
|---|---|
| To: | Lista Postgres ES <pgsql-es-ayuda(at)postgresql(dot)org> |
| Subject: | problema de desempeño con join basado en funcion similaridad |
| Date: | 2015-04-24 14:16:47 |
| Message-ID: | CAN3Qy4qbQg7e371P_D-Psuy-Y+cJJbKQeb_MT=t9FKCMoeMBPA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-es-ayuda |
hola Lista
Tenemos una base con twitter y queremos identificar aquellos que son
copiados y pegados pero que vendrian a ser el mismo y no se identifican
como retwitter...por ejemplo tenemos estos dos twitter
Nueva alianza de @ConnectAmericas y @camaracomerbog a disposición de
empresarios y empresas http://t.co/AQDeppDtso #Noticia
RT @bidcomercio: Nueva alianza de @connectamericas y @camaracomerbog a
disposición de empresarios y empresas http://t.co/f0Ky2564Lk #Noticia
Ambos son en esencia igual y por medio de la función de similaridad
(similarity extension pg_trgm) identificamos que poseen una calificación
0.725, lo que nos permite concluir que son iguales en esencia. El problema
surge cuando ya queremos comparar la tabla completa con 2'418.356
registros aproximadamente (la partición de un mes), pues el join entre
tablas seria la función de similaridad, la consulta que construí después de
leer e investigar fue:
SELECT set_limit(0.7);
select a.texto,b.texto,similarity(a.texto,b.texto)
from particiontwitter.tweets_2015_01 as a
join particiontwitter.tweets_2015_01 as b on
a.retweeted_status is NULL and LENGTH(a.texto) > 120
and b.retweeted_status is NULL and LENGTH(b.texto) > 120
and a.texto % b.texto
and a.id<>b.id
tengo los siguiente indices creados relevantes para la consulta:
CREATE INDEX idx_tweets_trgm_2015_01 ON particiontwitter.tweets_2015_01
USING gin (texto COLLATE pg_catalog."default" gin_trgm_ops);
CREATE INDEX idx_tweets_trgm_gist_2015_01 ON
particiontwitter.tweets_2015_01 USING gist (texto COLLATE
pg_catalog."default" gist_trgm_ops);
CREATE INDEX idx_tweets_comp3_2015_01 ON particiontwitter.tweets_2015_01
USING btree (retweeted_status COLLATE pg_catalog."default",
length(texto::text));
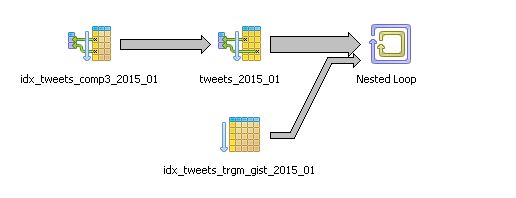
Y el plan de ejecución generado es:
Nested Loop (cost=487.15..485794.60 rows=38938 width=281)
-> Bitmap Heap Scan on tweets_2015_01 a (cost=487.06..14814.10
rows=10808 width=148)
Recheck Cond: ((retweeted_status IS NULL) AND (length((text)::text)
> 120))
-> Bitmap Index Scan on idx_tweets_comp3_2015_01
(cost=0.00..486.52 rows=10808 width=0)
Index Cond: ((retweeted_status IS NULL) AND
(length((texto)::text) > 120))
-> Index Scan using idx_tweets_trgm_gist_2015_01 on tweets_2015_01 b
(cost=0.08..43.56 rows=4 width=133)
Index Cond: ((a.texto)::text % (texto)::text)
Filter: ((retweeted_status IS NULL) AND ((a.id)::text <>
(id)::text) AND (length((texto)::text) > 120))
El problema es que no termina!!! lo he dejado correr un día y medio sobre
solo el mes de enero y no finalizo y supuestamente debemos correrlo para
todo lo que va el 2015... he intentado con FTS pero tampoco funciono...
como puedo hacer para optimizar mejor y/o replantear la consulta o en
general la manera de realizar la comparación que me permita obtener
resultados en un tiempo menor ? De antemano gracias!!!
| Attachment | Content-Type | Size |
|---|---|---|
|
image/jpeg | 10.9 KB |
| unknown_filename | text/plain | 157 bytes |
Responses
- Re: [pgsql-es-ayuda] problema de desempeño con join basado en funcion similaridad at 2015-04-24 15:09:43 from raul andrez gutierrez alejo
Browse pgsql-es-ayuda by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | raul andrez gutierrez alejo | 2015-04-24 15:09:43 | Re: [pgsql-es-ayuda] problema de desempeño con join basado en funcion similaridad |
| Previous Message | Patricia Recinos | 2015-04-23 20:31:24 | RE: Error Funciones y procedimientos |