Re: Update with last known location?
| From: | James David Smith <james(dot)david(dot)smith(at)gmail(dot)com> |
|---|---|
| To: | Erik Darling <edarling80(at)gmail(dot)com> |
| Cc: | PGSQL-Novice <pgsql-novice(at)postgresql(dot)org> |
| Subject: | Re: Update with last known location? |
| Date: | 2014-01-29 15:45:34 |
| Message-ID: | CAMu32ADSMa9qKi01N6=zp+Ybxw9FpjsS932AQbOCAFk0rLypgA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-novice |
Hi Erik/all,
I just tried that, but it's tricky. The 'extra' data is indeed coming
from the right side of the join, but it's hard to select only the max
from it. Maybe it's possible but I've not managed to do it. Here is
where I am, which is so very close.
SELECT
DISTINCT(a.ppid, a.point_time, a.the_geom) as row_that_needs_geom_updating,
max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
last_known_position_time
FROM
test a
INNER JOIN
(SELECT ppid,
point_time,
the_geom
FROM test
WHERE the_geom IS NOT NULL) b
ON b.point_time < a.point_time
AND a.ppid = b.ppid
WHERE a.the_geom IS NULL;
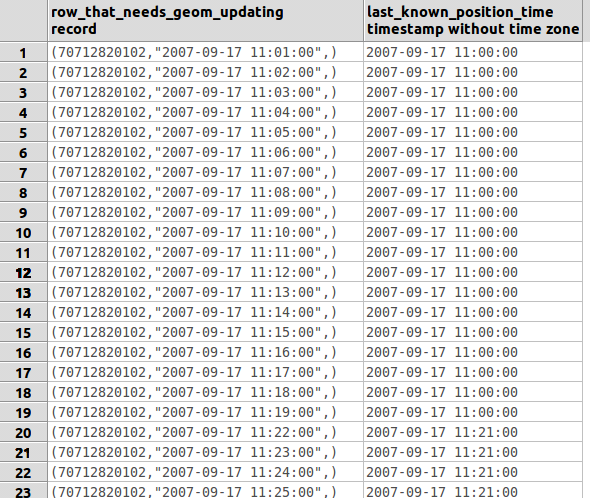
If you see attached screen-print, the output is the rows that I want.
However I've had to use DISTINCT to stop the duplication. Also I've
not managed to pull through 'the_geom' from the JOIN. I'm not sure
how. Anyone?
But it's kind of working. :-)
Worst case if I can't figure out how to solve this in one query I'll
have to store the result of the above, and then use it as a basis for
another query I think.
Thanks
James
On 29 January 2014 12:56, Erik Darling <edarling80(at)gmail(dot)com> wrote:
> I would try partitioning the second time you call row_number, perhaps by ID,
> and then selecting the MAX() from that, since I think the too much data
> you're referring to is coming from the right side of your join.
>
> On Jan 29, 2014 7:23 AM, "James David Smith" <james(dot)david(dot)smith(at)gmail(dot)com>
> wrote:
>>
>> On 28 January 2014 23:15, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>
>> wrote:
>> > On 29/01/14 11:00, Kevin Grittner wrote:
>> >>
>> >> James David Smith <james(dot)david(dot)smith(at)gmail(dot)com> wrote:
>> >>
>> >>> Given the data is so large I don't want to be taking the data out
>> >>> to a CSV or whatever and then loading it back in. I'd like to do
>> >>> this within the database using SQL. I thought I would be able to
>> >>> do this using a LOOP to be honest.
>> >>
>> >> I would be amazed if you couldn't do this with a single UPDATE
>> >> statement. I've generally found declarative forms of such work to
>> >> be at least one order of magnitude faster than going to either a PL
>> >> or a script approach. I would start by putting together a SELECT
>> >> query using window functions and maybe a CTE or two to list all the
>> >> primary keys which need updating and the new values they should
>> >> have. Once that SELECT was looking good, I would put it in the
>> >> FROM clause of an UPDATE statement.
>> >>
>> >> That should work, but if you are updating a large percentage of the
>> >> table, I would go one step further before running this against the
>> >> production tables. I would put a LIMIT on the above-mentioned
>> >> SELECT of something like 10000 rows, and script a loop that
>> >> alternates between the UPDATE and a VACUUM ANALYZE on the table.
>> >>
>> >> --
>> >> Kevin Grittner
>> >> EDB: http://www.enterprisedb.com
>> >> The Enterprise PostgreSQL Company
>> >>
>> >>
>> > James, you might consider dropping as many indexes on the table as you
>> > safely can, and rebuilding them after the mass update. If you have lots
>> > of
>> > such indexes, you will find this apprtoach to be a lot faster.
>> >
>> >
>> > Cheers,
>> > Gavin
>>
>> Hi all,
>>
>> Thanks for your help and assistance. I think that window functions,
>> and inparticular the PARTITION function, is 100% the way to go. I've
>> been concentrating on a SELECT statement for now and am close but not
>> quite close enough. The below query gets all the data I want, but
>> *too* much. What I've essentially done is:
>>
>> - Select all the rows that don't have any geom information
>> - Join them with all rows before this point that *do* have geom
>> information.
>> - Before doing this join, use partition to generate row numbers.
>>
>> The attached screen grab shows the result of my query below.
>> Unfortunately this is generating alot of joins that I don't want. This
>> won't be practical when doing it with 75,000 people.
>>
>> Thoughts and code suggestions very much appreciated... if needed I
>> could put together some SQL to create an example table?
>>
>> Thanks
>>
>> SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY
>> test.point_time) as test_row,
>> test.ppid as test_ppid,
>> test.point_time as test_point_time,
>> test.the_geom as test_the_geom,
>> a.ppid as a_ppid,
>> a.point_time as a_point_time,
>> a.the_geom as a_the_geom,
>> a.a_row
>> FROM test
>> LEFT JOIN (
>> SELECT the_geom,
>> ppid,
>> point_time,
>> row_number() OVER (ORDER BY ppid, point_time) as a_row
>> FROM test
>> WHERE the_geom IS NOT NULL) a
>> ON a.point_time < test.point_time
>> AND a.ppid = test.ppid
>> WHERE test.the_geom IS NULL
>> ORDER BY test.point_time)
>>
>>
>> --
>> Sent via pgsql-novice mailing list (pgsql-novice(at)postgresql(dot)org)
>> To make changes to your subscription:
>> http://www.postgresql.org/mailpref/pgsql-novice
>>
>
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 68.5 KB |
In response to
- Re: Update with last known location? at 2014-01-29 12:56:48 from Erik Darling
Responses
- Re: Update with last known location? at 2014-01-29 16:02:01 from Erik Darling
Browse pgsql-novice by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Erik Darling | 2014-01-29 16:02:01 | Re: Update with last known location? |
| Previous Message | Josh Kupershmidt | 2014-01-29 14:18:10 | Re: Couldn't get the database from heroku |