| From: | James David Smith <james(dot)david(dot)smith(at)gmail(dot)com> |
|---|---|
| To: | PGSQL-Novice <pgsql-novice(at)postgresql(dot)org> |
| Subject: | Re: Update with last known location? |
| Date: | 2014-01-29 12:20:27 |
| Message-ID: | CAMu32ABB4kr1B1A2n40eT6-xkGM7FKgQ4RxYtBKt=-_U33XX5Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-novice |
On 28 January 2014 23:15, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
> On 29/01/14 11:00, Kevin Grittner wrote:
>>
>> James David Smith <james(dot)david(dot)smith(at)gmail(dot)com> wrote:
>>
>>> Given the data is so large I don't want to be taking the data out
>>> to a CSV or whatever and then loading it back in. I'd like to do
>>> this within the database using SQL. I thought I would be able to
>>> do this using a LOOP to be honest.
>>
>> I would be amazed if you couldn't do this with a single UPDATE
>> statement. I've generally found declarative forms of such work to
>> be at least one order of magnitude faster than going to either a PL
>> or a script approach. I would start by putting together a SELECT
>> query using window functions and maybe a CTE or two to list all the
>> primary keys which need updating and the new values they should
>> have. Once that SELECT was looking good, I would put it in the
>> FROM clause of an UPDATE statement.
>>
>> That should work, but if you are updating a large percentage of the
>> table, I would go one step further before running this against the
>> production tables. I would put a LIMIT on the above-mentioned
>> SELECT of something like 10000 rows, and script a loop that
>> alternates between the UPDATE and a VACUUM ANALYZE on the table.
>>
>> --
>> Kevin Grittner
>> EDB: http://www.enterprisedb.com
>> The Enterprise PostgreSQL Company
>>
>>
> James, you might consider dropping as many indexes on the table as you
> safely can, and rebuilding them after the mass update. If you have lots of
> such indexes, you will find this apprtoach to be a lot faster.
>
>
> Cheers,
> Gavin
Hi all,
Thanks for your help and assistance. I think that window functions,
and inparticular the PARTITION function, is 100% the way to go. I've
been concentrating on a SELECT statement for now and am close but not
quite close enough. The below query gets all the data I want, but
*too* much. What I've essentially done is:
- Select all the rows that don't have any geom information
- Join them with all rows before this point that *do* have geom information.
- Before doing this join, use partition to generate row numbers.
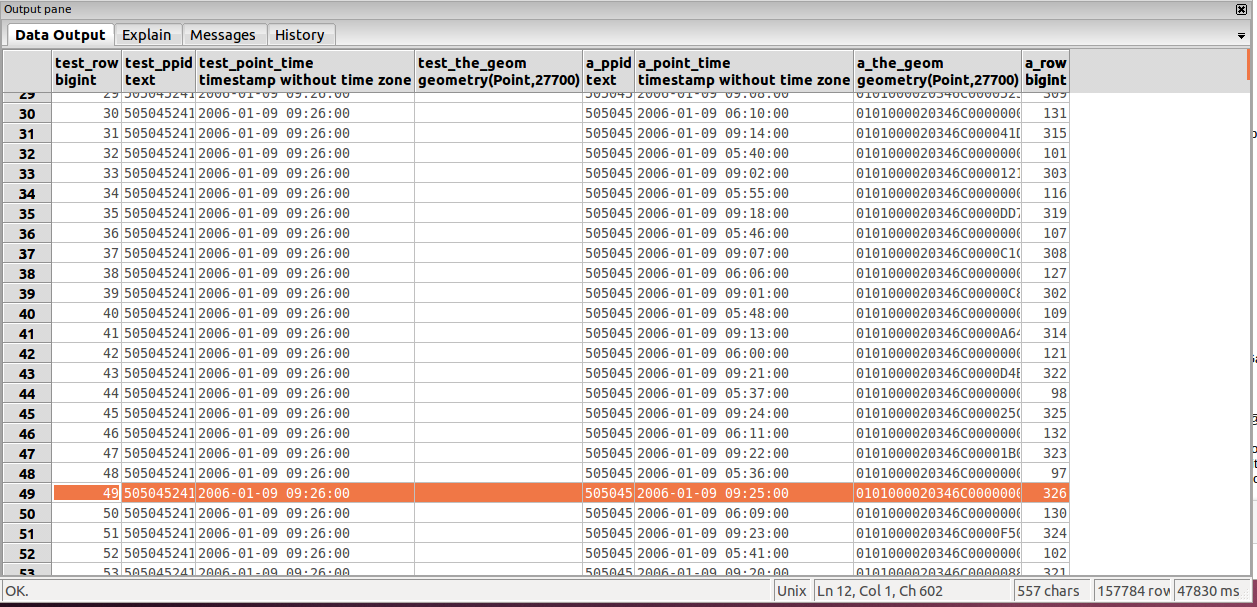
The attached screen grab shows the result of my query below.
Unfortunately this is generating alot of joins that I don't want. This
won't be practical when doing it with 75,000 people.
Thoughts and code suggestions very much appreciated... if needed I
could put together some SQL to create an example table?
Thanks
SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY
test.point_time) as test_row,
test.ppid as test_ppid,
test.point_time as test_point_time,
test.the_geom as test_the_geom,
a.ppid as a_ppid,
a.point_time as a_point_time,
a.the_geom as a_the_geom,
a.a_row
FROM test
LEFT JOIN (
SELECT the_geom,
ppid,
point_time,
row_number() OVER (ORDER BY ppid, point_time) as a_row
FROM test
WHERE the_geom IS NOT NULL) a
ON a.point_time < test.point_time
AND a.ppid = test.ppid
WHERE test.the_geom IS NULL
ORDER BY test.point_time)
| Attachment | Content-Type | Size |
|---|---|---|
| Selection_001.png | image/png | 118.1 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Erik Darling | 2014-01-29 12:56:48 | Re: Update with last known location? |
| Previous Message | Gavin Flower | 2014-01-28 23:15:28 | Re: Update with last known location? |
{kind=link}