| From: | Pavel Borisov <pashkin(dot)elfe(at)gmail(dot)com> |
|---|---|
| To: | Alexander Korotkov <aekorotkov(at)gmail(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, Aleksander Alekseev <aleksander(at)timescale(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org>, Mason Sharp <masonlists(at)gmail(dot)com>, vignesh C <vignesh21(at)gmail(dot)com> |
| Subject: | Re: POC: Lock updated tuples in tuple_update() and tuple_delete() |
| Date: | 2023-03-02 18:17:19 |
| Message-ID: | CALT9ZEHBWA5+u3H9rPRKM8UWK-Q5iZ2ph8FPsW7uxXGWM7HtjQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi, Alexander!
On Thu, 2 Mar 2023 at 18:53, Alexander Korotkov <aekorotkov(at)gmail(dot)com> wrote:
>
> Hi, Pavel!
>
> On Thu, Mar 2, 2023 at 1:29 PM Pavel Borisov <pashkin(dot)elfe(at)gmail(dot)com> wrote:
> > > Let's see the performance results for the patchset. I'll properly
> > > revise the comments if results will be good.
> > >
> > > Pavel, could you please re-run your tests over revised patchset?
> >
> > Since last time I've improved the test to avoid significant series
> > differences due to AWS storage access variation that is seen in [1].
> > I.e. each series of tests is run on a tmpfs with newly inited pgbench
> > tables and vacuum. Also, I've added a test for low-concurrency updates
> > where the locking optimization isn't expected to improve performance,
> > just to make sure the patches don't make things worse.
> >
> > The tests are as follows:
> > 1. Heap updates with high tuple concurrency:
> > Prepare without pkeys (pgbench -d postgres -i -I dtGv -s 10 --unlogged-tables)
> > Update tellers 100 rows, 50 conns ( pgbench postgres -f
> > ./update-only-tellers.sql -s 10 -P10 -M prepared -T 600 -j 5 -c 50 )
> >
> > Result: Average of 5 series with patches (0001+0002) is around 5%
> > faster than both master and patch 0001. Still, there are some
> > fluctuations between different series of the measurements of the same
> > patch, but much less than in [1]
>
> Thank you for running this that fast!
>
> So, it appears that 0001 patch has no effect. So, we probably should
> consider to drop 0001 patch and consider just 0002 patch.
>
> The attached patch v12 contains v11 0002 patch extracted separately.
> Please, add it to the performance comparison. Thanks.
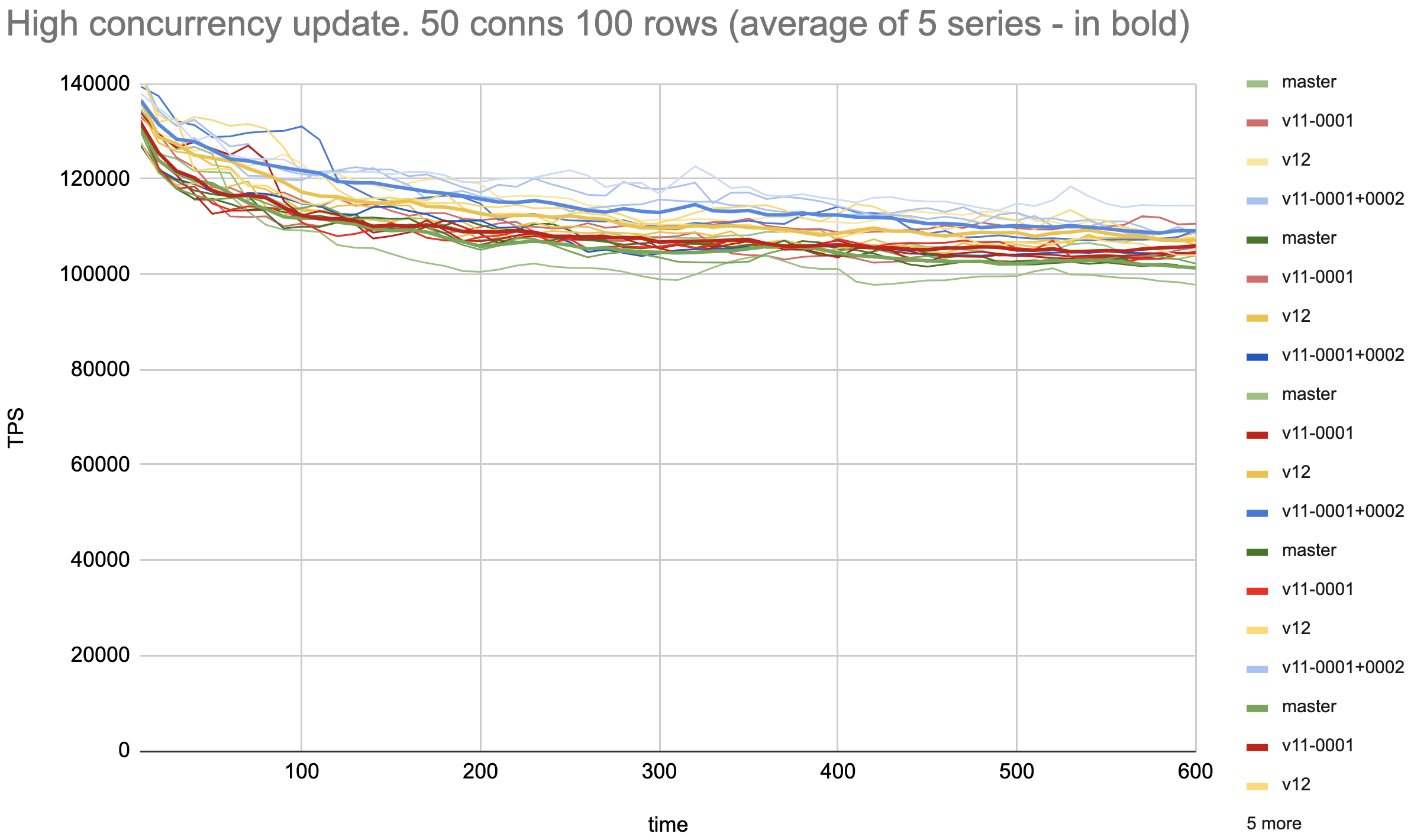
I've done a benchmarking on a full series of four variants: master vs
v11-0001 vs v11-0001+0002 vs v12 in the same configuration as in the
previous measurement. The results are as follows:
1. Heap updates with high tuple concurrency:
Average of 5 series v11-0001+0002 is around 7% faster than the master.
I need to note that while v11-0001+0002 shows consistent performance
improvement over the master, its value can not be determined more
precisely than a couple of percents even with averaging. So I'd
suppose we may not conclude from the results if a more subtle
difference between v11-0001+0002 vs v12 (and master vs v11-0001)
really exists.
2. Heap updates with high tuple concurrency:
All patches and master are still the same within a tolerance of
less than 0.7%.
Overall patch v11-0001+0002 doesn't show performance degradation so I
don't see why to apply only patch 0002 skipping 0001.
Regards,
Pavel Borisov,
Supabase.
| Attachment | Content-Type | Size |
|---|---|---|
| lo-concurrency-11-12.png | image/png | 249.0 KB |
| hi-concurrency-11-12.png | image/png | 416.9 KB |
| hi-concurrency-11-12.csv | text/csv | 10.7 KB |
| lo-concurrency-11-12.csv | text/csv | 8.5 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tomas Vondra | 2023-03-02 18:27:00 | Re: Add LZ4 compression in pg_dump |
| Previous Message | Jehan-Guillaume de Rorthais | 2023-03-02 18:15:30 | Re: Memory leak from ExecutorState context? |
{kind=link}
{kind=link}