| From: | Yuya Watari <watari(dot)yuya(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org> |
| Cc: | Ashutosh Bapat <ashutosh(dot)bapat(dot)oss(at)gmail(dot)com>, Dmitry Dolgov <9erthalion6(at)gmail(dot)com>, PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org>, jian he <jian(dot)universality(at)gmail(dot)com>, Alena Rybakina <lena(dot)ribackina(at)yandex(dot)ru>, Andrei Lepikhov <a(dot)lepikhov(at)postgrespro(dot)ru>, David Rowley <dgrowleyml(at)gmail(dot)com>, Thom Brown <thom(at)linux(dot)com>, Zhang Mingli <zmlpostgres(at)gmail(dot)com> |
| Subject: | Re: [PoC] Reducing planning time when tables have many partitions |
| Date: | 2025-02-11 23:29:33 |
| Message-ID: | CAJ2pMkb4BGWpcfr36HHyakTG6zYtA+d=eCL7=pHJNt0Nz35W5Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello all,
On Tue, Jan 7, 2025 at 3:56 PM Yuya Watari <watari(dot)yuya(at)gmail(dot)com> wrote:
>
> Overall, v30 offers a balanced approach to both planning time and
> memory usage. I would greatly appreciate any feedback, reviews, or
> further suggestions.
While looking at the patches, I noticed a simpler way to implement
this optimization, so I refactored the code.
1. Reducing Redundancy
What I thought was not good in the previous patches is quoted below.
The previous approach required getting the parent representation of
the given Relids and then introducing child members if they could
satisfy certain conditions based on the parent representation. This
resulted in repetitive code changes that had a negative impact on code
maintainability.
=====
+ Relids top_parent_relids;
+ EquivalenceChildMemberIterator it;
+ EquivalenceMember *em;
+
+ /*
+ * First, we translate the given Relids to their top-level parents. This
+ * is required because an EquivalenceClass contains only parent
+ * EquivalenceMembers, and we have to translate top-level ones to get
+ * child members. We can skip such translations if we now see top-level
+ * ones, i.e., when top_parent_rel is NULL. See the
+ * find_relids_top_parents()'s definition for more details.
+ */
+ top_parent_relids = find_relids_top_parents(root, relids);
...
- foreach(lc, ec->ec_members)
+ /*
+ * If we need to see child EquivalenceMembers, we access them via
+ * EquivalenceChildMemberIterator during the iteration.
+ */
+ setup_eclass_child_member_iterator(&it, ec);
+ while ((em = eclass_child_member_iterator_next(&it)) != NULL)
{
- EquivalenceMember *em = (EquivalenceMember *) lfirst(lc);
...
+ /*
+ * If child EquivalenceMembers may match the request, we add and
+ * iterate over them by calling iterate_child_rel_equivalences().
+ */
+ if (top_parent_relids != NULL && !em->em_is_child &&
+ bms_is_subset(em->em_relids, top_parent_relids))
+ iterate_child_rel_equivalences(&it, root, ec, em, relids);
=====
In the new v31 patch, these procedures have been encapsulated inside
an iterator, reducing the overall patch size by about 300 lines. A
diff between v30 and v31 is attached for quick reference. I hope this
change will make the patches easier to review.
2. Experimental Setup
I ran experiments to test the new version of the patches. In the
experiments, I tested three queries, A and B (from [1]) and C (from
[2]). The patch versions tested were:
* Master
* v30
* v31
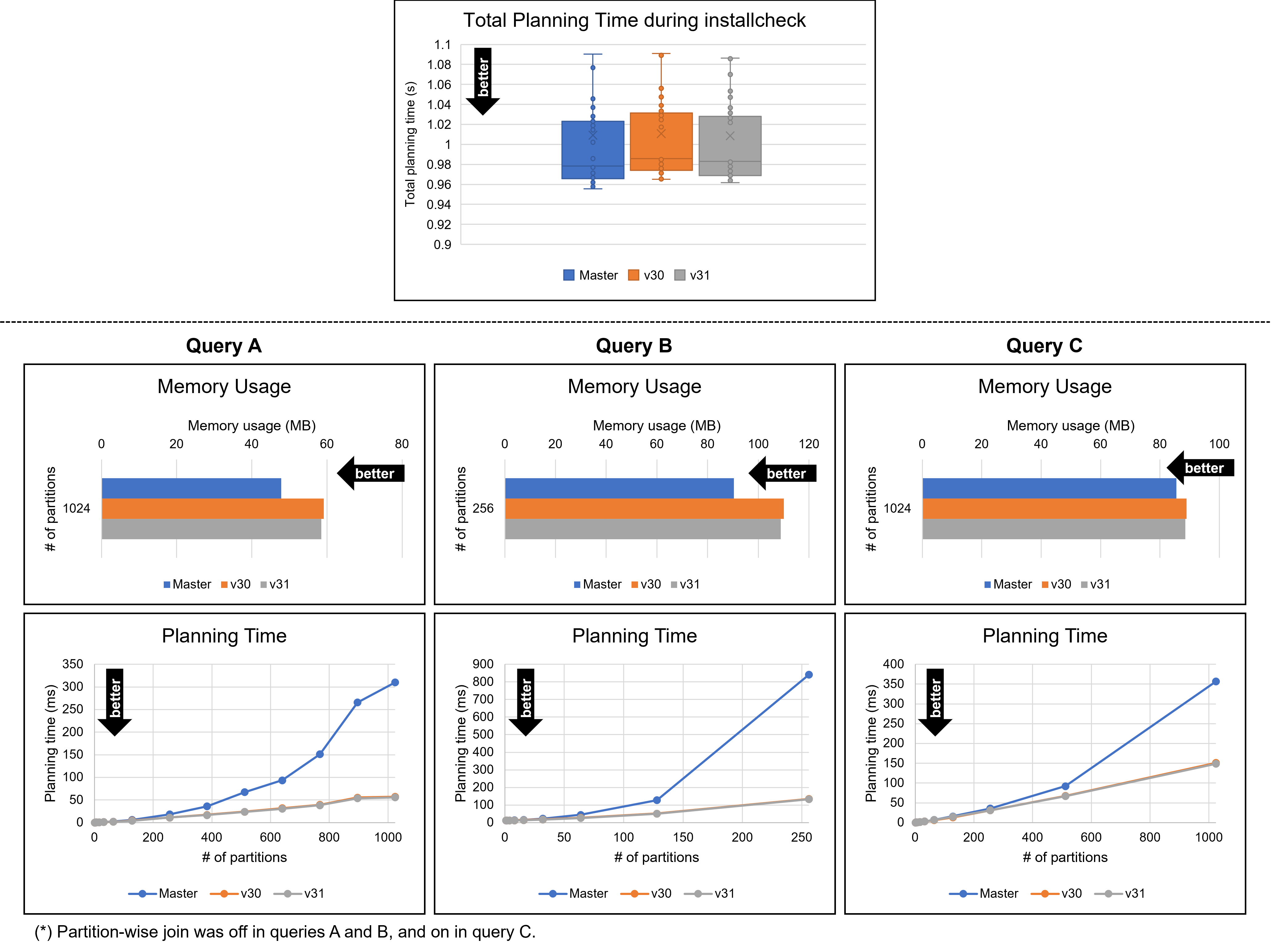
3. Memory Usage
The table below and the attached figure show the memory usage for the
three versions. Here, "n" is the number of partitions per table, and
"PWJ" stands for partition-wise join. For all queries, v31
demonstrated a slight reduction compared to v30.
Table 1: Memory usage (MB)
-----------------------------------------------------
Query | n | PWJ | Master | v30 | v31
-----------------------------------------------------
A | 1024 | OFF | 47.822 | 59.184 | 58.479
A | 1024 | ON | 123.348 | 134.709 | 134.005
B | 256 | OFF | 90.410 | 110.085 | 108.911
B | 256 | ON | 5198.580 | 5218.255 | 5217.081
C | 1024 | OFF | 36.854 | 38.023 | 37.787
C | 1024 | ON | 85.575 | 88.933 | 88.531
-----------------------------------------------------
4. Planning Time (installcheck)
The following tables and the attached figure show the total planning
time during installcheck. The purpose of this test is to confirm that
the patches did not cause regressions in non-partitioned or
less-partitioned cases. The results indicate that any regression in
v31 was either non-existent or negligible, and slightly smaller than
in v30.
Table 2: Total planning time during installcheck (seconds)
------------------------------------------
Version | Mean | Median | Stddev
------------------------------------------
Master | 1.009155 | 0.978412 | 0.085537
v30 | 1.010750 | 0.985674 | 0.052681
v31 | 1.008644 | 0.983096 | 0.059137
------------------------------------------
Table 3: Speedup for installcheck (higher is better)
---------------------------
Version | Mean | Median
---------------------------
v30 | 99.8% | 99.3%
v31 | 100.1% | 99.5%
---------------------------
5. Planning Time (Queries A, B, and C)
The following tables and the attached figure present the planning
times and the corresponding speedups. In these experiments, v31
outperformed v30 for both small and large sizes, and the design
changes introduced in v31 did not appear to cause any regressions.
Table 4: Planning time for query A (ms)
----------------------------------
n | Master | v30 | v31
----------------------------------
1 | 0.246 | 0.249 | 0.246
2 | 0.276 | 0.281 | 0.275
4 | 0.344 | 0.352 | 0.343
8 | 0.440 | 0.454 | 0.439
16 | 0.629 | 0.619 | 0.607
32 | 1.143 | 1.051 | 1.043
64 | 2.296 | 2.176 | 2.103
128 | 6.321 | 4.633 | 4.174
256 | 18.530 | 11.180 | 11.123
384 | 35.876 | 17.286 | 16.595
512 | 67.345 | 24.072 | 23.608
640 | 93.604 | 31.745 | 30.681
768 | 151.207 | 39.276 | 38.428
896 | 265.949 | 55.430 | 53.876
1024 | 310.239 | 56.925 | 55.630
----------------------------------
Table 5: Speedup of query A (higher is better)
------------------------
n | v30 | v31
------------------------
1 | 98.6% | 99.9%
2 | 98.1% | 100.3%
4 | 97.6% | 100.1%
8 | 97.0% | 100.3%
16 | 101.5% | 103.6%
32 | 108.8% | 109.6%
64 | 105.5% | 109.2%
128 | 136.4% | 151.4%
256 | 165.7% | 166.6%
384 | 207.5% | 216.2%
512 | 279.8% | 285.3%
640 | 294.9% | 305.1%
768 | 385.0% | 393.5%
896 | 479.8% | 493.6%
1024 | 545.0% | 557.7%
------------------------
Table 6: Planning time for query B (ms)
-----------------------------------
n | Master | v30 | v31
-----------------------------------
1 | 12.074 | 12.099 | 11.981
2 | 11.617 | 11.636 | 11.503
4 | 12.102 | 12.026 | 11.876
8 | 13.325 | 12.857 | 12.688
16 | 16.142 | 14.673 | 14.436
32 | 22.995 | 18.165 | 17.775
64 | 44.591 | 27.220 | 26.690
128 | 127.826 | 51.541 | 50.088
256 | 840.771 | 135.511 | 132.788
-----------------------------------
Table 7: Speedup of query B (higher is better)
-----------------------
n | v30 | v31
-----------------------
1 | 99.8% | 100.8%
2 | 99.8% | 101.0%
4 | 100.6% | 101.9%
8 | 103.6% | 105.0%
16 | 110.0% | 111.8%
32 | 126.6% | 129.4%
64 | 163.8% | 167.1%
128 | 248.0% | 255.2%
256 | 620.4% | 633.2%
-----------------------
Table 8: Planning time for query C (ms)
------------------------------------
n | Master | v30 | v31
------------------------------------
1 | 0.272 | 0.273 | 0.273
2 | 0.386 | 0.386 | 0.385
4 | 0.537 | 0.534 | 0.535
8 | 0.842 | 0.837 | 0.832
16 | 1.585 | 1.567 | 1.562
32 | 3.265 | 3.224 | 3.176
64 | 6.914 | 6.446 | 6.896
128 | 15.906 | 13.356 | 14.509
256 | 35.962 | 31.218 | 31.112
512 | 92.177 | 67.573 | 66.822
1024 | 356.469 | 151.058 | 148.820
------------------------------------
Table 9: Speedup of query C (higher is better)
------------------------
n | v30 | v31
------------------------
1 | 99.5% | 99.7%
2 | 100.0% | 100.2%
4 | 100.4% | 100.2%
8 | 100.7% | 101.3%
16 | 101.2% | 101.5%
32 | 101.3% | 102.8%
64 | 107.3% | 100.3%
128 | 119.1% | 109.6%
256 | 115.2% | 115.6%
512 | 136.4% | 137.9%
1024 | 236.0% | 239.5%
------------------------
6. Conclusion
Compared to previous versions, v31 reduces code size while maintaining
(or slightly improving) high speedups and low memory consumption. I
would greatly appreciate any feedback, reviews or further suggestions.
[1] https://www.postgresql.org/message-id/CAJ2pMkYcKHFBD_OMUSVyhYSQU0-j9T6NZ0pL6pwbZsUCohWc7Q%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAJ2pMkZZHrhgQ5UV0y%2BSTKqx7XVGzENMhL98UbKM-OArvK9dmA%40mail.gmail.com
--
Best regards,
Yuya Watari
| Attachment | Content-Type | Size |
|---|---|---|
| diff-v30-v31.txt | text/plain | 35.2 KB |
| figure.png | image/png | 321.2 KB |
| v31-0001-Speed-up-searches-for-child-EquivalenceMembers.patch | application/octet-stream | 54.7 KB |
| v31-0002-Resolve-conflict-with-commit-66c0185.patch | application/octet-stream | 6.4 KB |
| v31-0003-Introduce-indexes-for-RestrictInfo.patch | application/octet-stream | 41.5 KB |
| v31-0004-Introduce-RestrictInfoIterator-to-reduce-memory-.patch | application/octet-stream | 17.1 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Michail Nikolaev | 2025-02-11 23:39:09 | Re: [BUG?] check_exclusion_or_unique_constraint false negative |
| Previous Message | Andres Freund | 2025-02-11 23:13:26 | Re: Bump soft open file limit (RLIMIT_NOFILE) to hard limit on startup |
{kind=link}