| From: | Yuya Watari <watari(dot)yuya(at)gmail(dot)com> |
|---|---|
| To: | Dmitry Dolgov <9erthalion6(at)gmail(dot)com> |
| Cc: | PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org>, jian he <jian(dot)universality(at)gmail(dot)com>, Ashutosh Bapat <ashutosh(dot)bapat(dot)oss(at)gmail(dot)com>, Alena Rybakina <lena(dot)ribackina(at)yandex(dot)ru>, Andrei Lepikhov <a(dot)lepikhov(at)postgrespro(dot)ru>, David Rowley <dgrowleyml(at)gmail(dot)com>, Thom Brown <thom(at)linux(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Zhang Mingli <zmlpostgres(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Subject: | Re: [PoC] Reducing planning time when tables have many partitions |
| Date: | 2024-12-02 08:51:56 |
| Message-ID: | CAJ2pMkZMKwdjYRUGA0=za4SUrgpBJ5_JDYuVeG=Esbv1dKSouQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello Dmitry,
I really appreciate you reviewing these patches.
On Thu, Nov 28, 2024 at 4:51 AM Dmitry Dolgov <9erthalion6(at)gmail(dot)com> wrote:
>
> Few random notes after quickly looking through the first patch:
>
> * There are patterns like this scattered around, it looks somewhat confusing:
>
> + /* See the comments in get_eclass_for_sort_expr() to see how this works. */
> + top_parent_rel_relids = find_relids_top_parents(root, rel->relids);
>
> It's not immediately clear which part of get_eclass_for_sort_expr is
> relevant, or one have to read the whole function first. Probably better to
> omit the superficial commentary on the call site, and instead expand the
> commentary for the find_relids_top_parents itself?
Thank you for pointing this out. As you said, those comments are not
helpful for understanding, and I also agree that expanding the actual
comments is better. I fixed this in v28.
> * The patch series features likely/unlikely since v20, but don't see any
> discussion about that. Did you notice any visible boost from that? I wonder
> how necessary that is.
I'm sorry I haven't tested the effects of these likely/unlikely. To
discuss the need for them, I have added the removals of these
likely/unlikely as v28-0006 and v28-0007, which are attached to this
email. I would like to decide whether to adopt these removals after
discussion here.
There are two uses of likely and unlikely in the original patches:
1. likely in the find_relids_top_parents() macro (quoted below)
The find_relids_top_parents() macro has likely. This macro replaces
the given Relids as their parents. If they are all already parents, it
simply returns NULL. This is to avoid slowing down for non-partitioned
cases. For such cases, we don't need to do anything to introduce child
EquivalenceMembers. The patches effectively skip this by checking
whether the returned Relids is NULL.
If there are no partitioned tables in the given query,
root->top_parent_relid_array is set to NULL and the macro can return
NULL immediately. I assumed that non-partitioned use cases are common,
I used likely here. In the attached patches, I removed this in
v28-0006 to confirm its effects.
=====
#define find_relids_top_parents(root, relids) \
(likely((root)->top_parent_relid_array == NULL) \
? NULL : find_relids_top_parents_slow(root, relids))
extern Relids find_relids_top_parents_slow(PlannerInfo *root, Relids relids);
=====
2. unlikely, which checks if top_parent_relids is null (quoted below)
The caller of the find_relids_top_parents() macro has unlikely for the
same reason. I removed this in v28-0007.
=====
top_parent_rel = find_relids_top_parents(root, rel);
...
/*
* If child EquivalenceMembers may match the request, we add and
* iterate over them by calling iterate_child_rel_equivalences().
*/
if (unlikely(top_parent_rel != NULL) && !cur_em->em_is_child &&
bms_equal(cur_em->em_relids, top_parent_rel))
iterate_child_rel_equivalences(&it, root, cur_ec, cur_em, rel);
=====
> The referenced email containst some benchmark results. But shouldn't the
> benchmark be repeated after those design changes you're talking about?
Thank you for pointing this out. I ran the same benchmarks as in [1].
1. Versions used in the benchmarks
I used the following five versions in the benchmarks:
* Master,
* v23: The version just before the design change (introduction of an
iterator over child EquivalenceMembers). I rebased this old version
for these benchmarks,
* ~v28-0005: Same as v27,
* ~v28-0006: ~v28-0005 with "likely" removed,
* ~v28-0007: ~v28-0006 with "unlikely" removed.
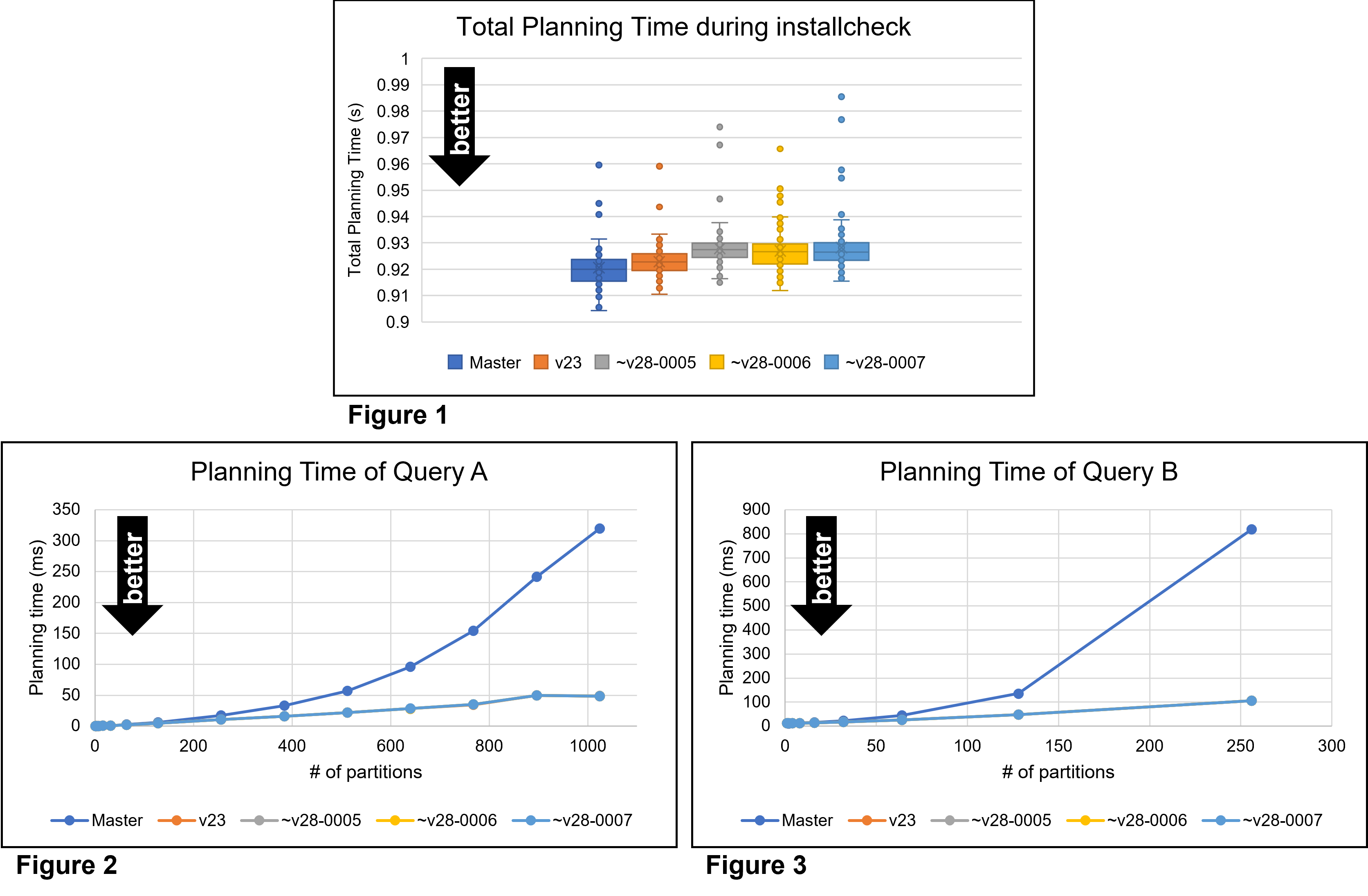
2. Small size cases (make installcheck)
This benchmark is to confirm regressions with the patches. I ran 'make
installcheck' and measured the planning times of all queries executed
during the tests.
Table 1: Total planning time for installcheck (seconds)
--------------------------------------------
Program | Mean | Median | Stddev
--------------------------------------------
Master | 0.920580 | 0.920022 | 0.007805
v23 | 0.922827 | 0.922795 | 0.006311
~v28-0005 | 0.927891 | 0.927387 | 0.007835
~v28-0006 | 0.926924 | 0.926663 | 0.007905
~v28-0007 | 0.928182 | 0.926434 | 0.010324
--------------------------------------------
Table 2: Speedup for installcheck (higher is better)
----------------------------
Program | Mean | Median
----------------------------
v23 | 99.8% | 99.7%
~v28-0005 | 99.2% | 99.2%
~v28-0006 | 99.3% | 99.3%
~v28-0007 | 99.2% | 99.3%
----------------------------
3. Large size cases (queries A and B)
I also evaluated the patches using queries A and B, which can be found
at [2]. Both queries join partitioned tables.
Table 3: Planning time of query A
(n: the number of partitions of each table)
(lower is better)
-------------------------------------------------------------
n | Master | v23 | ~v28-0005 | ~v28-0006 | ~v28-0007
-------------------------------------------------------------
1 | 0.245 | 0.250 | 0.253 | 0.252 | 0.250
2 | 0.266 | 0.273 | 0.274 | 0.274 | 0.275
4 | 0.339 | 0.351 | 0.352 | 0.350 | 0.350
8 | 0.435 | 0.443 | 0.446 | 0.442 | 0.443
16 | 0.619 | 0.623 | 0.625 | 0.626 | 0.625
32 | 1.065 | 1.009 | 1.018 | 1.022 | 1.025
64 | 2.520 | 2.197 | 2.196 | 2.202 | 2.204
128 | 6.076 | 4.634 | 4.610 | 4.588 | 4.563
256 | 17.447 | 10.416 | 10.576 | 10.463 | 10.545
384 | 33.068 | 16.023 | 16.019 | 16.015 | 16.092
512 | 57.213 | 21.793 | 21.930 | 21.882 | 21.972
640 | 96.241 | 28.208 | 28.441 | 28.205 | 28.308
768 | 154.046 | 34.724 | 35.059 | 35.012 | 35.001
896 | 241.509 | 49.596 | 49.902 | 49.631 | 49.829
1024 | 319.269 | 48.297 | 48.892 | 48.417 | 48.384
-------------------------------------------------------------
Table 4: Speedup of query A (higher is better)
---------------------------------------------------
n | v23 | ~v28-0005 | ~v28-0006 | ~v28-0007
---------------------------------------------------
1 | 98.1% | 96.6% | 97.2% | 97.8%
2 | 97.3% | 96.9% | 97.0% | 96.8%
4 | 96.8% | 96.3% | 97.0% | 96.9%
8 | 98.0% | 97.4% | 98.4% | 98.2%
16 | 99.3% | 99.0% | 98.8% | 99.0%
32 | 105.6% | 104.7% | 104.2% | 103.9%
64 | 114.7% | 114.8% | 114.4% | 114.4%
128 | 131.1% | 131.8% | 132.4% | 133.2%
256 | 167.5% | 165.0% | 166.8% | 165.5%
384 | 206.4% | 206.4% | 206.5% | 205.5%
512 | 262.5% | 260.9% | 261.5% | 260.4%
640 | 341.2% | 338.4% | 341.2% | 340.0%
768 | 443.6% | 439.4% | 440.0% | 440.1%
896 | 487.0% | 484.0% | 486.6% | 484.7%
1024 | 661.0% | 653.0% | 659.4% | 659.9%
---------------------------------------------------
Table 5: Planning time of query B (lower is better)
-------------------------------------------------------------
n | Master | v23 | ~v28-0005 | ~v28-0006 | ~v28-0007
-------------------------------------------------------------
1 | 11.759 | 11.952 | 12.017 | 11.999 | 11.975
2 | 11.334 | 11.474 | 11.538 | 11.525 | 11.522
4 | 11.790 | 11.866 | 11.894 | 11.849 | 11.930
8 | 13.029 | 12.799 | 12.818 | 12.798 | 12.806
16 | 15.649 | 14.373 | 14.353 | 14.404 | 14.384
32 | 22.462 | 17.733 | 17.861 | 17.908 | 17.830
64 | 44.593 | 26.238 | 26.461 | 26.512 | 26.578
128 | 135.504 | 47.256 | 47.394 | 47.372 | 47.537
256 | 818.483 | 105.361 | 105.749 | 105.619 | 105.772
-------------------------------------------------------------
Table 6: Speedup of query B (higher is better)
--------------------------------------------------
n | v23 | ~v28-0005 | ~v28-0006 | ~v28-0007
--------------------------------------------------
1 | 98.4% | 97.8% | 98.0% | 98.2%
2 | 98.8% | 98.2% | 98.3% | 98.4%
4 | 99.4% | 99.1% | 99.5% | 98.8%
8 | 101.8% | 101.6% | 101.8% | 101.7%
16 | 108.9% | 109.0% | 108.6% | 108.8%
32 | 126.7% | 125.8% | 125.4% | 126.0%
64 | 170.0% | 168.5% | 168.2% | 167.8%
128 | 286.7% | 285.9% | 286.0% | 285.0%
256 | 776.8% | 774.0% | 774.9% | 773.8%
--------------------------------------------------
4. Discussion
First of all, tables 1, 2 and the figure attached to this email show
that likely and unlikely do not have the effect I expected. Rather,
tables 3, 4, 5 and 6 imply that they can have a negative effect on
queries A and B. So it is better to remove these likely and unlikely.
For the design change, the benchmark results show that it may cause
some regression, especially for smaller sizes. However, Figure 1 also
shows that the regression is much smaller than its variance. This
design change is intended to improve code maintainability. The
regression is small enough that I think these results are acceptable.
What do you think about this?
[1] https://www.postgresql.org/message-id/CAJ2pMkZk-Nr=yCKrGfGLu35gK-D179QPyxaqtJMUkO86y1NmSA@mail.gmail.com
[2] https://www.postgresql.org/message-id/CAJ2pMkYcKHFBD_OMUSVyhYSQU0-j9T6NZ0pL6pwbZsUCohWc7Q@mail.gmail.com
--
Best regards,
Yuya Watari
| Attachment | Content-Type | Size |
|---|---|---|
| figure.png | image/png | 234.9 KB |
| v28-0001-Speed-up-searches-for-child-EquivalenceMembers.patch | application/octet-stream | 62.3 KB |
| v28-0002-Introduce-indexes-for-RestrictInfo.patch | application/octet-stream | 42.9 KB |
| v28-0003-Move-EquivalenceClass-indexes-to-PlannerInfo.patch | application/octet-stream | 14.4 KB |
| v28-0004-Rename-add_eq_member-to-add_parent_eq_member.patch | application/octet-stream | 5.2 KB |
| v28-0005-Resolve-conflict-with-commit-66c0185.patch | application/octet-stream | 6.4 KB |
| v28-0006-Don-t-use-likely-in-find_relids_top_parents.patch | application/octet-stream | 955 bytes |
| v28-0007-Don-t-use-unlikely-top_parent-NULL.patch | application/octet-stream | 4.5 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Amit Kapila | 2024-12-02 08:56:07 | Re: Virtual generated columns |
| Previous Message | Peter Eisentraut | 2024-12-02 08:51:17 | Use Python "Limited API" in PL/Python |
{kind=link}