| From: | Benjamin Manes <ben(dot)manes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Peter Geoghegan <pg(at)bowt(dot)ie>, Andrey Borodin <x4mmm(at)yandex-team(dot)ru>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Arslan Gumerov <garsthe1st(at)gmail(dot)com>, Andrey Chausov <dxahtepb(at)gmail(dot)com>, geymer_98(at)mail(dot)ru, dafi913(at)yandex(dot)ru, edigaryev(dot)ig(at)phystech(dot)edu |
| Subject: | Re: [Patch][WiP] Tweaked LRU for shared buffers |
| Date: | 2019-02-16 02:03:44 |
| Message-ID: | CAGu0=MO4auR78F_gN788eRPQ=HsEp8wsq+Z1mK6i3ZvQFvujtA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
>
> No, I "synchronized scans" are an optimization to reduce I/O when multiple
> processes do sequential scan on the same table.
Oh, very neat. Thanks!
Interesting. I assume the trace is essentially a log of which blocks were
> requested? Is there some trace format specification somewhere?
>
Yes, whatever constitutes a cache key (block address, item hash, etc). We
write parsers for each trace so there isn't a format requirement. The
parsers produce a 64-bit int stream of keys, which are broadcasted to each
policy via an actor framework. The trace files can be text or binary,
optionally compressed (xz preferred). The ARC traces are block I/O and this
is their format description
<https://www.dropbox.com/sh/9ii9sc7spcgzrth/j1CJ72HiWa/Papers/ARCTraces/README.txt>,
so perhaps something similar? That parser is only 5 lines of custom code
<https://github.com/ben-manes/caffeine/blob/b752c586f7bf143f774a51a0a10593ae3b77802b/simulator/src/main/java/com/github/benmanes/caffeine/cache/simulator/parser/arc/ArcTraceReader.java#L36-L42>
.
On Fri, Feb 15, 2019 at 5:51 PM Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>
wrote:
> On 2/16/19 1:48 AM, Benjamin Manes wrote:
> > Hi,
> >
> > I was not involved with Andrey and his team's work, which looks like a
> > very promising first pass. I can try to clarify a few minor details.
> >
> > What is CAR? Did you mean ARC, perhaps?
> >
> >
> > CAR is the Clock variants of ARC: CAR: Clock with Adaptive Replacement
> > <
> https://www.usenix.org/legacy/publications/library/proceedings/fast04/tech/full_papers/bansal/bansal.pdf
> >
> >
>
> Thanks, will check.
>
> > I believe the main interest in ARC is its claim of adaptability with
> > high hit rates. Unfortunately the reality is less impressive as it fails
> > to handle many frequency workloads, e.g. poor scan resistance, and the
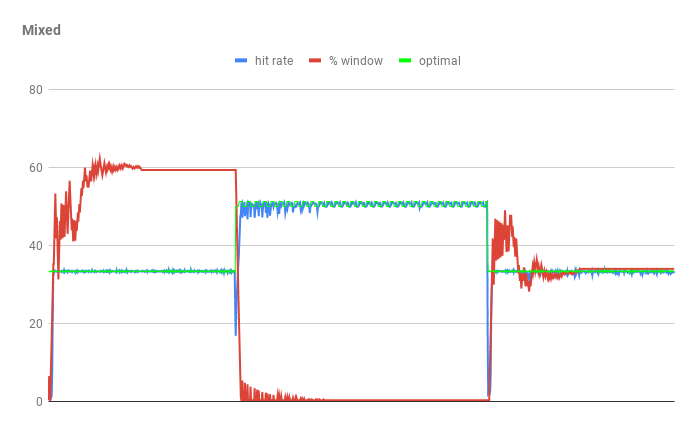
> > adaptivity is poor due to the accesses being quite noisy. For W-TinyLFU,
> > we have recent improvements which show near perfect adaptivity
> > <
> https://user-images.githubusercontent.com/378614/52891655-2979e380-3141-11e9-91b3-00002a3cc80b.png
> > in
> > our stress case that results in double the hit rate of ARC and is less
> > than 1% from optimal.
> >
>
> Interesting.
>
> > Can you point us to the thread/email discussing those ideas? I have
> > tried searching through archives, but I haven't found anything :-(
> >
> >
> > This thread
> > <
> https://www.postgresql.org/message-id/1526057854777-0.post%40n3.nabble.com
> >
> > doesn't explain Andrey's work, but includes my minor contribution. The
> > longer thread discusses the interest in CAR, et al.
> >
>
> Thanks.
>
> > Are you suggesting to get rid of the buffer rings we use for
> > sequential scans, for example? IMHO that's going to be tricky, e.g.
> > because of synchronized sequential scans.
> >
> >
> > If you mean "synchronized" in terms of multi-threading and locks, then
> > this is a solved problem
> > <http://highscalability.com/blog/2016/1/25/design-of-a-modern-cache.html>
> in
> > terms of caching.
>
> No, I "synchronized scans" are an optimization to reduce I/O when
> multiple processes do sequential scan on the same table. Say one process
> is half-way through the table, when another process starts another scan.
> Instead of scanning it from block #0 we start at the position of the
> first process (at which point they "synchronize") and then wrap around
> to read the beginning.
>
> I was under the impression that this somehow depends on the small
> circular buffers, but I've now checked the code and I see that's bogus.
>
>
> > My limited understanding is that the buffer rings are
> > used to protect the cache from being polluted by scans which flush the
> > LRU-like algorithms. This allows those policies to capture more frequent
> > items. It also avoids lock contention on the cache due to writes caused
> > by misses, where Clock allows lock-free reads but uses a global lock on
> > writes. A smarter cache eviction policy and concurrency model can handle
> > this without needing buffer rings to compensate.
> >
>
> Right - that's the purpose of circular buffers.
>
> > Somebody should write a patch to make buffer eviction completely
> > random, without aiming to get it committed. That isn't as bad of a
> > strategy as it sounds, and it would help with assessing improvements
> > in this area.
> >
> >
> > A related and helpful patch would be to capture the access log and
> > provide anonymized traces. We have a simulator
> > <https://github.com/ben-manes/caffeine/wiki/Simulator> with dozens of
> > policies to quickly provide a breakdown. That would let you know the hit
> > rates before deciding on the policy to adopt.
> >
>
> Interesting. I assume the trace is essentially a log of which blocks
> were requested? Is there some trace format specification somewhere?
>
> cheers
>
> --
> Tomas Vondra http://www.2ndQuadrant.com
> PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
>
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Andres Freund | 2019-02-16 02:13:09 | Re: Patch for SortSupport implementation on inet/cdir |
| Previous Message | Tomas Vondra | 2019-02-16 01:51:24 | Re: [Patch][WiP] Tweaked LRU for shared buffers |
{kind=link}