| From: | Thomas Munro <thomas(dot)munro(at)enterprisedb(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: PG 11 feature count |
| Date: | 2018-05-19 02:20:54 |
| Message-ID: | CAEepm=0mBNsxWKUinUfR0mZ_06EMPoHOBvyOZL8zAkV8NqJoDw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Sat, May 19, 2018 at 5:08 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> On 17 May 2018 at 18:29, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
>> 7.4 280
>> 8.0 238
>> 8.1 187
>> 8.2 230
>> 8.3 237
>> 8.4 330
>> 9.0 252
>> 9.1 213
>> 9.2 250
>> 9.3 187
>> 9.4 217
>> 9.5 200
>> 9.6 220
>> 10 194
>> 11 167
>
> It would be useful to combine that with the CF app data showing number
> of patches submitted and number of features rejected. Not available
> for all time, but certainly goes back a few years now.
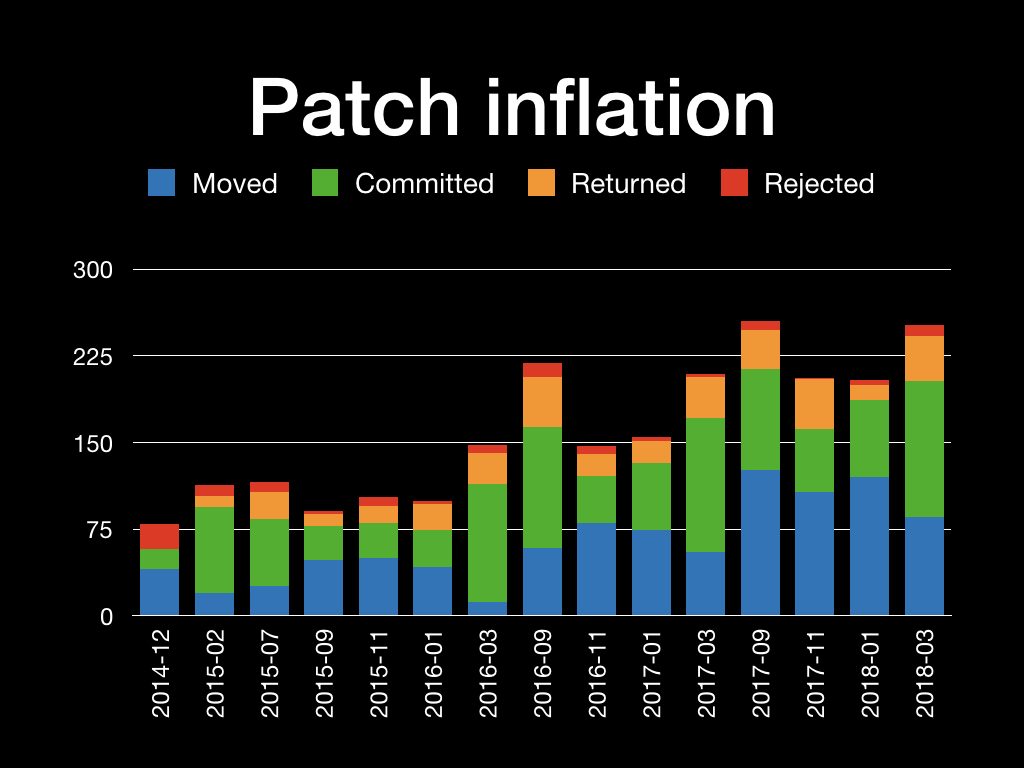
Here is a plot of that, from a slide deck I'll be showing at PGCon.
It travels in the opposite direction. Obviously those numbers give
the same weight to major features like, say, PROCEDUREs and minor
refactoring patches like, say, improvements around <stdbool.h>, so it
doesn't tell you anything about "feature" growth.
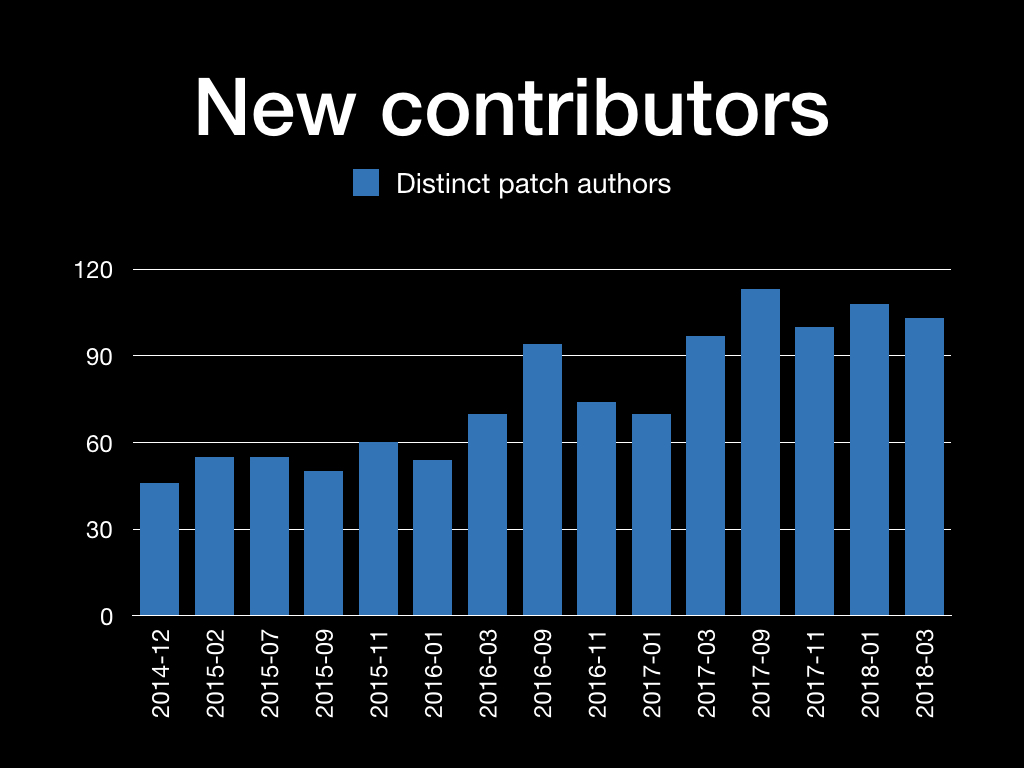
On the other hand, it is clearly correlated with the number of patch
authors contributing to each Commitfest. That number is going up
(hi!). Each recent Commitfest has had 10-15 names never seen before
in it. Many of those are single-patch authors AKA drive-by
contributions, which are of course very welcome, and the number of
those is increasing, but clearly some go on to join the pool of
regular contributors. Here are some relevant numbers, using data
since the current Commitfest epoch began in December 2014:
84 people [co]authored exactly 1 CF entry
40 people [co]authored exactly 2
22 3
16 4
16 5
8 6
11 7
13 8
4 9
4 10
3 11
4 12
4 13
3 14
1 15
6 16
1 17
3 18
3 19
3 20
1 21
1 23
2 25
1 27
1 29
1 30
1 35
2 39
1 40
1 41
1 44
1 45
1 46
1 50
1 51
1 52
1 55
1 58
1 61
1 66
1 72
1 73
1 77
1 81
1 83
1 86
1 116
1 219
Looking at the individual names of people who have [co]authored 20+
Commitfest entries, I see:
219 Michael Paquier
116 Peter Eisentraut
86 Kyotaro Horiguchi
83 Thomas Munro
81 Fabien Coelho
77 Pavel Stehule
73 Tomas Vondra
72 Alexander Korotkov
66 Peter Geoghegan
61 Masahiko Sawada
58 Amit Kapila
55 Etsuro Fujita
52 Craig Ringer
51 Haribabu Kommi
50 David Rowley
46 Heikki Linnakangas
45 Tom Lane
44 Amit Langote
41 Jeff Janes
40 Simon Riggs
39 Takayuki Tsunakawa
39 Petr Jelínek
35 Ashutosh Bapat
30 Andres Freund
29 Álvaro Herrera
27 Andreas Karlsson
25 Magnus Hagander
25 Arthur Zakirov
23 Fedor Sigaev
21 Marko Tiikkaja
20 Nikita Glukhov
20 Anastasia Lubennikova
20 Aleksander Alekseev
From those names, it looks like the size of the permanent crew is
really determined by the number of engineers who work (or worked) at
companies that (1) fund database development and (2) actively
contribute work upstream as a matter of policy. Things like whether
we accept Github pull requests might affect the rate of drive-by
contributions, and there *might* be some kind of link there: for
example SKIP LOCKED, a drive-by contribution, was a bit of a gateway
for me. Maybe there is some complexity threshold above which a pull
request wouldn't really be the right forum though; maybe it's better
for small slam dunk patches that don't require complex discussion?
For what it's worth, I wasn't put off by the mailing list culture. On
the contrary, I was able to lurk for a while and see how things work
around here. Figuring out how to interact with the PostgreSQL hackers
is possibly the least of your worries if you want to start hacking on
transaction isolation or whatever else (though admittedly it may be
harder for non-native speakers of the langauage, who I have enormous
respect for). But I'm also in favour of using modern tools. For
example, if we accepted pull requests we could also have .travis.yml
and appveyor.yml files in the tree, so that every pull request is
automatically tested on Windows and Linux, and you'd see the green
flags when considering it. I have been meaning to get around to
proposing CI control files for the tree, but I'm not yet convinced
that my CI control files are good enough (certainly the Windows one
isn't). Bridging the gap between mailing list patches and a public
git branch/pull request model is exactly what I wanted to do with
cfbot.cputube.org, while keeping out of the way of the existing
workflow.
I note that a major feature was proposed, reviewed and committed
without up-to-date patches on -hackers in this cycle, and that passed
without comment. Admittedly the branch in question was in a repo
hosted on git.postgresql.org and not an external-to-the-project repo.
I think it's quite interesting that other projects bigger than us are
also mailing list-centric and also build tooling around that that
keeps out of the way, like patchwork.kernel.org. See also
https://softwareengineering.stackexchange.com/questions/191961/why-do-some-big-projects-like-git-and-debian-only-use-a-mailing-list-and-not-a
and https://lwn.net/Articles/702177/ . I also think different types
of projects attract different types of people; web
development/UX-centric projects are more likely to want to use tools
from that universe rather than the text adventure apparently favoured
by some database and operating system hackers. Just watch out for
grues.
--
Thomas Munro
http://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
| patches.jpeg | image/jpeg | 178.6 KB |
| authors.jpeg | image/jpeg | 166.3 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Andrew Dunstan | 2018-05-19 02:58:21 | Re: perl checking |
| Previous Message | Justin Pryzby | 2018-05-19 01:56:53 | Re: Should we add GUCs to allow partition pruning to be disabled? |
{kind=link}
{kind=link}