Re: Urgente, postgres down
| From: | "Carlos T(dot) Groero Carmona" <ctonetg(at)gmail(dot)com> |
|---|---|
| To: | Horacio Miranda <hmiranda(at)gmail(dot)com> |
| Cc: | Jaime Casanova <jaime(dot)casanova(at)2ndquadrant(dot)com>, Lista PostgreSql <pgsql-es-ayuda(at)postgresql(dot)org> |
| Subject: | Re: Urgente, postgres down |
| Date: | 2019-02-14 05:21:41 |
| Message-ID: | CABh6Tc2uWxqzM9XfUdK19TEpkoDAEsUGzz7paSh-d7+57ZF+Ag@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-es-ayuda |
Horacio gracias por sus comentarios.
Dejame comentar que en mi caso tengo template0 y template1, pude conectarme
a template1 y hacerle vacuum a toda la base de datos, pero no puedo
conectarme a template0, esta situacion me preocupa.
datname | max | percentage
-----------+------------+-----------
template0 | 1586628037 | 75.55
template1 | 277797489 | 13.22
(2 rows)
La base de datos de production esta al 28%, como le dije, las base de datos
a las cuales puedo conectarme no me preocupan, solo template0 porque no
puedo hacerle vacuum.
Estaba pensando en disminuir la configuracion de autovacuum_freeze_max_age a
1 billon forzando autovacuum a encargarse de esa base de datos.
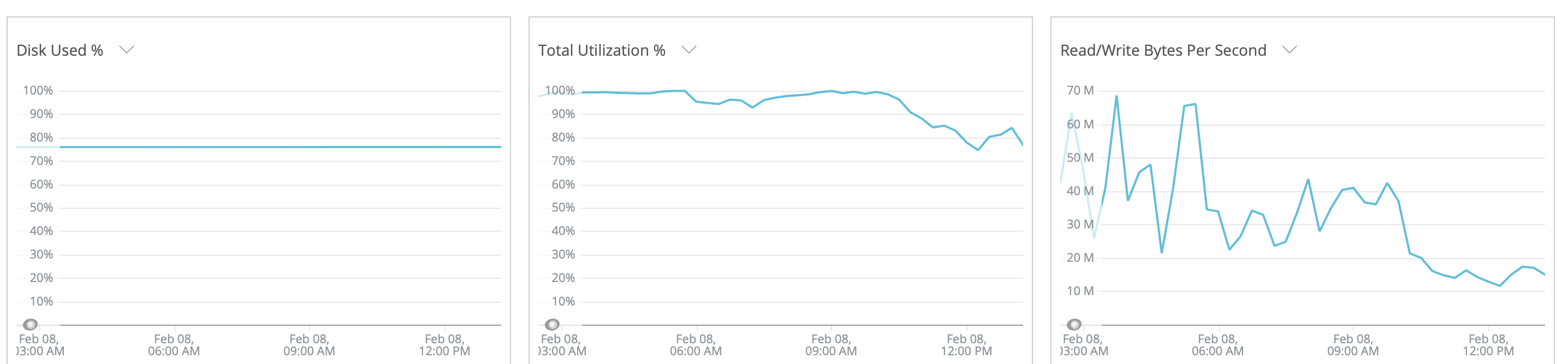
Sobre el uso de I/O adjunto 2 screenshoot tomados en NewRelic el viernes
pasado, que fue cuando tuve que desactivar autovacuum por casi 2 horas
esperando que el sistema volviera a su normalidad, despues de estar dos
horas estabilizado lo volvi a activar y desminui el cost_limit, desde
entonces no hemos tenido mas problema con la base de datos.
Saludos,
Carlos.
On Wed, Feb 13, 2019 at 4:06 PM Horacio Miranda <hmiranda(at)gmail(dot)com> wrote:
>
> On 14/02/2019 6:18 AM, Carlos T. Groero Carmona wrote:
>
> Horacio gracia spor su respuesta, abajo los comentarios despues de revisar
> cada uno de sus puntos.
>
> On Mon, Feb 11, 2019 at 4:35 AM Horacio Miranda <hmiranda(at)gmail(dot)com>
> wrote:
>
>> Creo que hay varios problemas aquí, podemos ver los más basicos.
>>
> Estoy de acuerdo, tratando de figurar cuales, y super agradecido por la
> ayuda brindada
>
>> Revisa que las llaves Foraneas tengan indices.
>>
>> https://dba.stackexchange.com/questions/121976/discover-missing-foreign-keys-and-or-indexes
>>
> Despues de usar la informaci'on en el link que me mandas y hacer una
> comparaci'on entre el uso de sequencias y de indeces, puedo decir que no
> tenemos falta de indices en la base de datos, o al menos solo 3 tablas han
> usado mas secuencias que indexes y el tamano de estas tablas es inferior a
> 10MB. Asi que creo que no es el uso de indices, tenemos de sobra, eso si
> puedo asegurarle, estoy tratando de revisar con el equipo de desarrollo y
> me aprueben quitar aquellos donde no se requieren o no se usan, tratando de
> aumentar la velocidad de escritura.
>
>> Dices que tienes tablas particionadas, esto solo sirve si las consultas
>> tienen en el Where el criterio de la particion, si son por fechas que las
>> consultas en la tabla gigantesca sean por fechas. de lo contrario no te va
>> a ayudar mucho.
>>
> Si, las consultas que usamos utilizan los indices correctamente, lcomo
> quiera estoy usando pgBadger para identificar las queries mas lentas y
> analizar como puedo mejorar su rendimiento.
>
>> Los parametros el S.O. los ajustaste para manejar una base de datos
>> grande ? Usas un Filesystem como XFS ? ( me gusta más que ext3 o ext4 )
>> pero es algo personal.
>>
> El kernel del SO me permite usar hasta 137 GB of sahed memory, solo estoy
> utilizando 24 GB en el shared_bufer.
>
>> Sobre los IO. iostat -m -x /dev/sd? 3 ( que te dice, contención ? ).
>>
> avg-cpu: %user %nice %system %iowait %steal %idle
>
> 16.90 0.00 6.39 1.54 0.00 75.17
>
>
> Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s
> avgrq-sz avgqu-sz await r_await w_await svctm %util
> dm-5 0.00 0.00 5.94 41.94 0.22 0.16 16.47
> 0.01 0.17 11.46 3.76 0.31 1.48
>
>> sar ( que te dice sobre las contenciones ? ).
>>
> 07:30:01 AM CPU %user %nice %system %iowait %steal
> %idle
>
> 07:40:01 AM all 28.48 0.00 12.28 2.41 0.00
> 56.83
>
> 07:50:01 AM all 27.73 0.00 11.98 2.21 0.00
> 58.07
>
> 08:00:01 AM all 28.74 0.00 12.38 2.06 0.00
> 56.82
>
> 08:10:01 AM all 32.54 0.00 14.27 2.26 0.00
> 50.93
>
> 08:20:01 AM all 31.96 0.00 13.95 2.25 0.00
> 51.84
>
> 08:30:01 AM all 33.87 0.00 14.66 2.41 0.00
> 49.06
>
> 08:40:01 AM all 33.18 0.00 14.45 2.57 0.00
> 49.80
>
> 08:50:01 AM all 33.35 0.00 14.68 2.58 0.00
> 49.38
>
> 09:00:01 AM all 33.90 0.00 14.96 2.43 0.00
> 48.71
>
> 09:10:01 AM all 38.93 0.00 17.02 2.72 0.00
> 41.33
>
> 09:20:01 AM all 38.84 0.00 16.94 2.37 0.00
> 41.85
>
> Average: all 16.45 0.00 7.21 1.18 0.00
> 75.16
>
>> Los discos en la maquina real estan todos sanos ?
>>
> Si, lo unico que no contribuye mucho es que usamos SAN, por eso vamos a
> cambiar a otro servidor para usar SSD.
>
> No veo contención a nivel de disco, revisa de forma continua que le ocurre
> a la maquina ( mira datadog para monitoreo ) o si usas otra herramienta
> conecta el SO para capturar los IO de disco.
>
> La fuente de poder estan las dos activas ? ( una fuente puesta en un
>> servidor pero desenchufada va a desabilitar los cache de las controladora.
>>
> El servidor esta en RackSpace, voy a preguntar, aunque no creo que eso sea
> posible, ese servicio cuesta bien caro.
>
> no importa este punto, no hay contención de discos.
>
> Los cache estan funcionando ? ( supongo que tienes algo como HP o DELL, o
>> alguna marga que no sea un PC armado corriendo aquí ).
>>
> Tenemos un Dell Inc. PowerEdge R720. CPU:24 RAM:512
>
>> el shmmax esta reajustado de acuerdo al shared buffers ? ( no puedes
>> tener un shared buffer grande si no tienes el S.O. en sintonía con la base
>> de datos. ( elimina el Swap si puedes ), y no asignes más del 80% a la base
>> de datos si es lo unico que corre ahi ).
>>
> Si tienes una maquina con 512G RAM usa la RAM para porgres lo que más
> puedas.
>
> Usa este link para estimar los parámetros. https://pgtune.leopard.in.ua/#/
>
> cat /proc/sys/kernel/shmmax = 137438953472 = ~137GB
>
> postgres=# show shared_buffers;
>
> shared_buffers
>
> ----------------
>
> 24GB
>
> (1 row)
>
>> Sobre python ( lee sobre pool y postgresql ).
>>
>> Si usas jdbc ( pasa el parametro *-Djava.security.egd=file:/dev/./urandom
>> )*
>>
>> http://ruleoftech.com/2016/avoiding-jvm-delays-caused-by-random-number-generation
>> ).
>>
> He estado leyendo sobre como y la importancia de usar un connection pool,
> en estos momentos no es una opcion cambiar la arquitectura ni modificar el
> codigo de los sistemas para manejar mas eficiente la forma de escribir en
> la BD, por eso propuse revisar la configuracion del connection pool que
> trae implementado Ruby/Rails, que si se esta utilizando se esta usando la
> configuration por defecto, que es 5, pero hay varios parametros que afentan
> el numero final de conectiones por servidores, no solo dependiendo del
> valor especificado en la configuarion del pool, he estado leyendo bastante
> al respecto desde que hablamos hace como 6 semanas atras de la necesidad de
> usar pgBouncer. Esto resume bastante bien como funciona Ruby/Rails:
>
> https://devcenter.heroku.com/articles/concurrency-and-database-connections#connection-pool
>
> Puede que no sea importante, pero /dev/random es super malo para muchas
>> conexiones sobre todo si no usas pooling con java.
>>
> Una pregunta, cuando dices /dev/random te refires al FS? este es el mio:
> /dev/mapper/X-X
>
> No, en Linux todo es un archivo, /dev/random es un dispositivo que crea
> numeros random en base a entropia ( para tener numeros realmente randoms )
> ahora el problema es que la entropia no esta disponible siempre, para
> mejorar el rendimientos en programas que usan cryptografia yo uso
> /dev/urandom, apache /dev/urandom, etc. Hay varios articulos que hablan
> sobre que es un mito urbano que /dev/random es mejor que /dev/urandom ya
> que ambos usan la misma libreria para generar los numeros aleatorios.
>
>
>
>> Es super raro que la base template1 este tan fragmentada, algo debe estar
>> escribiendo y borrando cosas. revisa que tabla es, puede que sea alguna de
>> estadisticas.
>>
> Analizando el crecimiento diaria (cada 24H) he visto que el promedio
> diario de crecimiento del XID es alrededor de 44millones, esto afecta todas
> las base de datos en el servidor por igual, es decir todas crecen con el
> mismo indice, incluyendo template1 y template0. La unica que me preocupa
> seriamente es template0, pues no puedo ejecutar un vacuum y no estoy seguro
> si esta "base de datos" podria dejarme el servidor fuera de servicio
> nuevamente, actualmente el XID de template1 es 1 562 227 160 representando
> el 74% de 2.1 billon.
>
> Seria bueno saber si existe alguna manera de hacerle vacuum a template0 o
> en el caso que template1 alcance los 2.1billon que pasaria?
>
> Template1 es como decirlo el corazón de postgres, si esa base esta muerta,
> todo lo medas muere con ella ( en realidad puedes copiar los directorios
> por debajo en terioría pero solo me toco hacer una chancheria como esa una
> sola vez en mi vida con postgres 6.2 y ResiserFS o algo como eso, se
> recupero, nunca perdi un dato de producción con postgres y por eso toco
> madera.
>
> Este problema se ve super interesante, hay alguna forma de generar tu data
> de forma random ? ( tengo maquinas en mi ambiente de pruebas grandes para
> jugar ).
>
>
>
>
>
| Attachment | Content-Type | Size |
|---|---|---|

|
image/png | 50.1 KB |
| Screen Shot 2019-02-13 at 11.16.22 PM.png | image/png | 166.7 KB |
{kind=link}
In response to
- Re: Urgente, postgres down at 2019-02-13 22:06:52 from Horacio Miranda
Responses
- Re: Urgente, postgres down at 2019-02-14 09:01:51 from Francisco Olarte
- Re: Urgente, postgres down at 2019-02-14 09:08:58 from Horacio Miranda
Browse pgsql-es-ayuda by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Francisco Olarte | 2019-02-14 09:01:51 | Re: Urgente, postgres down |
| Previous Message | Horacio Miranda | 2019-02-13 22:06:52 | Re: Urgente, postgres down |