Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Michael Paquier <michael(at)paquier(dot)xyz> |
| Cc: | Sami Imseih <samimseih(at)gmail(dot)com>, Ivan Bykov <I(dot)Bykov(at)modernsys(dot)ru>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET |
| Date: | 2025-03-18 04:24:42 |
| Message-ID: | CAApHDvrdj0LZ_udM9X6-TZS88GxnANN_arutPFv4k1_h53py4Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Mon, 17 Mar 2025 at 13:53, Michael Paquier <michael(at)paquier(dot)xyz> wrote:
> So, here is attached a counter-proposal, where we can simply added a
> counter tracking a node count in _jumbleNode() to add more entropy to
> the mix, incrementing it as well for NULL nodes.
I had a look at this and it seems the main difference will be that
this patch will protect against the case that a given node is non-null
but has a custom jumble function which selects to not jumble anything
in some cases. Since Ivan's patch only adds jumbling for non-null,
that could lead to the same bug if a custom jumble function decided to
not jumble anything at all.
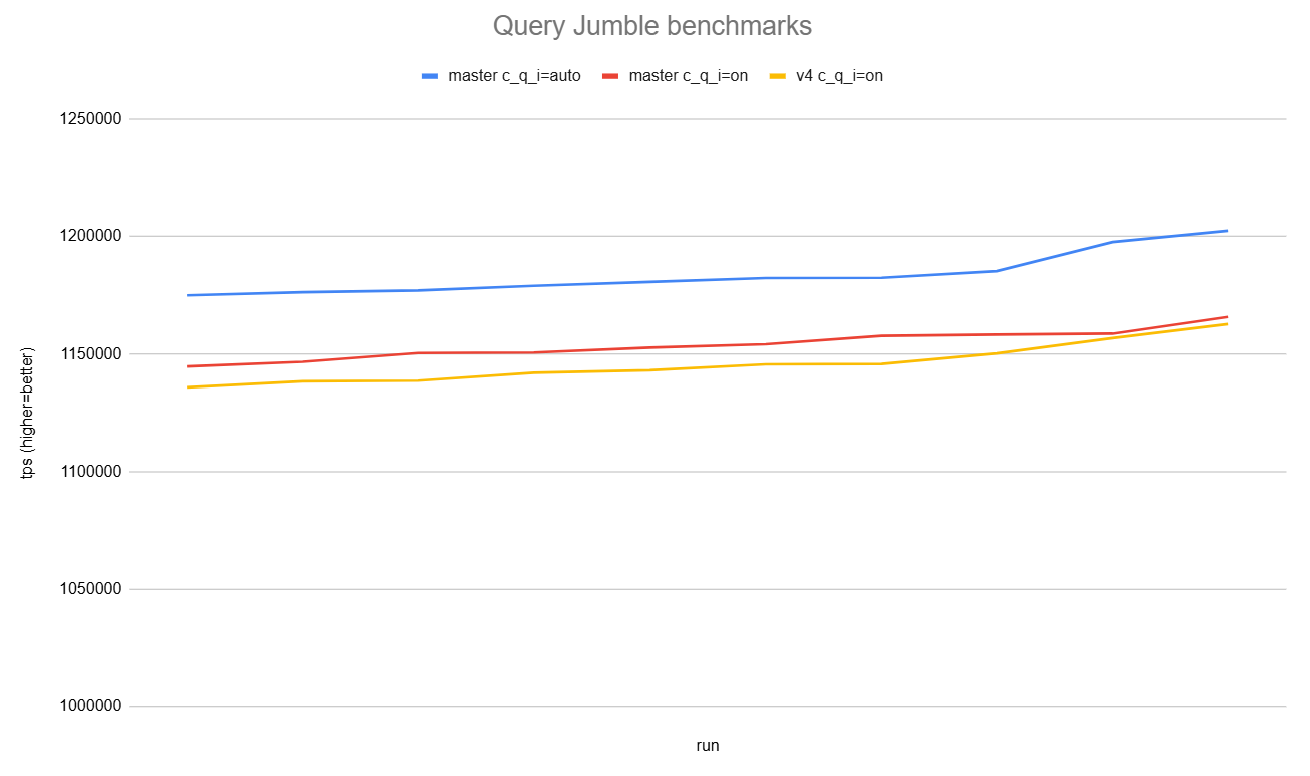
FWIW, I did the same test to jumble all make check queries with your
patch, same as [1]:
master: 73.66 milliseconds
0001-Query-ID-Calculation-Fix-Variant-B.patch: 80.36 milliseconds
v4-0001-Add-more-entropy-to-query-jumbling.patch: 88.84 milliseconds
I know you've said in [2] that you're not worried about performance,
but I wanted to see if that's true... I can measure the cost of
compute_query_id=on with pgbench -S workload on my AMD 3990x machine.
I tried with that on "auto", then with "on" with master and again with
your v4 patch when set to "on":
(the -c 156 -j 156 is just there to ensure this machine properly
clocks up, which it still seems hesitant to do sometimes, even with
the performance power settings)
drowley(at)amd3990x:~$ echo master compute_query_id = auto && for i in
{1..10}; do pg_ctl stop -D pgdata > /dev/null && pg_ctl start -D
pgdata -l pg.log > /dev/null && pgbench -n -M simple -S -T 60 -c 156
-j 156 postgres | grep tps; done
master compute_query_id = auto
tps = 1202451.945998
tps = 1197645.856236
tps = 1182345.403291
tps = 1182440.562773
tps = 1180731.003390
tps = 1185277.478449
tps = 1174983.732094
tps = 1176310.828235
tps = 1179040.622103
tps = 1177068.520272
drowley(at)amd3990x:~$ echo master compute_query_id = on && for i in
{1..10}; do pg_ctl stop -D pgdata > /dev/null && pg_ctl start -D
pgdata -l pg.log > /dev/null && pgbench -n -M simple -S -T 60 -c 156
-j 156 postgres | grep tps; done
master compute_query_id = on
tps = 1158684.006821
tps = 1165808.752641
tps = 1158269.999683
tps = 1146730.269628
tps = 1154200.484194
tps = 1152750.152235
tps = 1150438.486321
tps = 1150649.669337
tps = 1144745.761593
tps = 1157743.530383
drowley(at)amd3990x:~$ echo
v4-0001-Add-more-entropy-to-query-jumbling.patch compute_query_id = on
&& for i in {1..10}; do pg_ctl stop -D pgdata > /dev/null && pg_ctl
start -D pgdata -l pg.log > /dev/null && pgbench -n -M simple -S -T 60
-
c 156 -j 156 postgres | grep tps; done
v4-0001-Add-more-entropy-to-query-jumbling.patch compute_query_id = on
tps = 1156782.516710
tps = 1162780.019911
tps = 1142104.075069
tps = 1145651.299640
tps = 1143157.945891
tps = 1150275.033626
tps = 1145817.267485
tps = 1135915.694987
tps = 1138703.153873
tps = 1138436.802882
It's certainly hard to see much slowdown between master and v4, but it
is visible if I sort the results and put them in a line graph and
scale the vertical axis a bit. A 0.7% slowdown. See attached.
I didn't run the same test on the
0001-Query-ID-Calculation-Fix-Variant-B.patch patch, but with the
first set of results I posted above, you could assume it's less than
0.7% overhead. Locally, I did play around with internalising the
AppendJumble function so my compiler would compile a dedicated
JumbleNull function, which removes a bit of branching and code for the
memcpy. I managed to get it going a bit faster that way.
I do agree that your v4 fixes the issue at hand and I'm not going to
stand in your way if you want to proceed with it. However, from my
point of view, it seems that we could achieve the same goal with much
less overhead by just insisting that custom jumble functions always
jumble something. We could provide a jumble function to do that if the
custom function conditionally opts to jumble nothing. That would save
having to add this additional jumbling of the node count.
Also, am I right in thinking that there's no way for an extension to
add a custom jumble function? If so, then we have full control over
any custom jumble function. That would make it easier to ensure these
always jumble something.
David
[1] https://postgr.es/m/CAApHDvqaKySJdBf2v2_ybNuT=KObaUVBU4_5kgZfFTMSJr-Vmg@mail.gmail.com
[2] https://postgr.es/m/Z9flafNlH4-1YSJW@paquier.xyz
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 30.0 KB |
In response to
- Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET at 2025-03-17 00:52:46 from Michael Paquier
Responses
- Re: Query ID Calculation Fix for DISTINCT / ORDER BY and LIMIT / OFFSET at 2025-03-18 07:59:44 from Michael Paquier
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Daniil Davydov | 2025-03-18 04:26:49 | Re: Forbid to DROP temp tables of other sessions |
| Previous Message | Hayato Kuroda (Fujitsu) | 2025-03-18 04:20:20 | RE: long-standing data loss bug in initial sync of logical replication |