Re: [PATCH] Use optimized single-datum tuplesort in ExecSort
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Ronan Dunklau <ronan(dot)dunklau(at)aiven(dot)io> |
| Cc: | James Coleman <jtc331(at)gmail(dot)com>, PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org>, Ranier Vilela <ranier(dot)vf(at)gmail(dot)com>, Dilip Kumar <dilipbalaut(at)gmail(dot)com> |
| Subject: | Re: [PATCH] Use optimized single-datum tuplesort in ExecSort |
| Date: | 2021-07-13 03:15:24 |
| Message-ID: | CAApHDvrWV=v0qKsC9_BHqhCn9TusrNvCaZDz77StCO--fmgbKA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Tue, 13 Jul 2021 at 01:59, Ronan Dunklau <ronan(dot)dunklau(at)aiven(dot)io> wrote:
> > 3. This seems to be a bug fix where byval datum sorts do not properly
> > handle bounded sorts. I think that maybe that should be fixed and
> > backpatched. I don't see anything that says Datum sorts can't be
> > bounded and if there were some restriction on that I'd expect
> > tuplesort_set_bound() to fail when the Tuplesortstate had been set up
> > with tuplesort_begin_datum().
>
> I've kept this as-is for now, but I will remove it from my patch if it is
> deemed worthy of back-patching in your other thread.
I've now pushed that bug fix so it's fine to remove the change to
tuplesort.c now.
I also did a round of benchmarking on this patch using the attached
script. Anyone wanting to run it will need to run make installcheck
first to create the required tables.
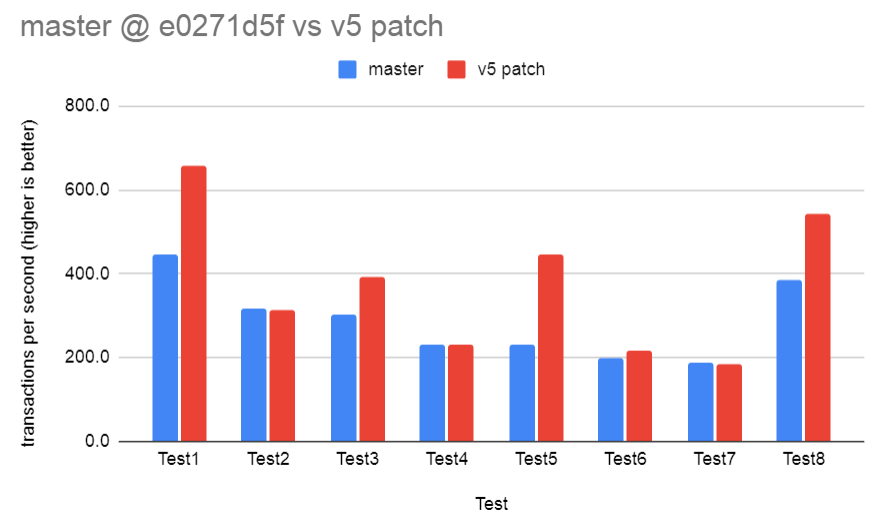
On an AMD machine, I got the following results.
Result in transactions per second.
Test master v5 patch compare
Test1 446.1 657.3 147.32%
Test2 315.8 314.0 99.44%
Test3 302.3 392.1 129.67%
Test4 232.7 230.7 99.12%
Test5 230.0 446.1 194.00%
Test6 199.5 217.9 109.23%
Test7 188.7 185.3 98.21%
Test8 385.4 544.0 141.17%
Tests 2, 4, 7 are designed to check if there is any regression from
doing the additional run-time checks to see if we're doing datumSort.
I measured a very small penalty from this. It's most visible in test7
with a drop of about 1.8%. Each test did OFFSET 1000000 as I didn't
want to measure the overhead of outputting tuples.
All the other tests show a pretty good gain. Test6 is testing a byref
type, so it appears the gains are not just from byval datums.
It would be good to see the benchmark script run on a few other
machines to get an idea if the gains and losses are consistent.
In theory, we likely could get rid of the small regression by having
two versions of ExecSort() and setting the correct one during
ExecInitSort() by setting the function pointer to the version we want
to use in sortstate->ss.ps.ExecProcNode. But maybe the small
regression is not worth going to that trouble over. I'm not aware of
any other executor nodes that have logic like that so maybe it would
be a bad idea to introduce something like that.
David
| Attachment | Content-Type | Size |
|---|---|---|
| sortbench.sh.txt | text/plain | 2.1 KB |
|
image/png | 33.4 KB |
In response to
- Re: [PATCH] Use optimized single-datum tuplesort in ExecSort at 2021-07-12 13:59:42 from Ronan Dunklau
Responses
- Re: [PATCH] Use optimized single-datum tuplesort in ExecSort at 2021-07-13 07:19:37 from Ronan Dunklau
- Re: [PATCH] Use optimized single-datum tuplesort in ExecSort at 2021-07-14 10:13:45 from David Rowley
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Peter Smith | 2021-07-13 03:25:48 | Re: row filtering for logical replication |
| Previous Message | Yugo NAGATA | 2021-07-13 02:59:49 | Question about non-blocking mode in libpq |