Re: Speed up Hash Join by teaching ExprState about hashing
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Alexey Dvoichenkov <alexey(at)hyperplane(dot)net> |
| Cc: | PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Re: Speed up Hash Join by teaching ExprState about hashing |
| Date: | 2024-08-14 23:36:57 |
| Message-ID: | CAApHDvpncdT9JJbnLrB7UU=E1LnK8JOm4w+vkO6mBak1NN1YEw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Sun, 11 Aug 2024 at 22:09, Alexey Dvoichenkov <alexey(at)hyperplane(dot)net> wrote:
> I like the idea so I started looking at this patch. I ran some tests,
> the query is an aggregation over a join of two tables with 5M rows,
> where "columns" is the number of join conditions. (Mostly the same as
> in your test.) The numbers are the average query run-time in seconds.
Thanks for running those tests.
I wondered if the hash table has 5M items that the non-predictable
memory access pattern when probing that table might be drowning out
some of the gains of producing hash values faster. I wrote the
attached script which creates a fairly small table but probes that
table much more than once per hash value. I tried to do that in a way
that didn't read or process lots of shared buffers so as not to put
additional pressure on the CPU caches, which could evict cache lines
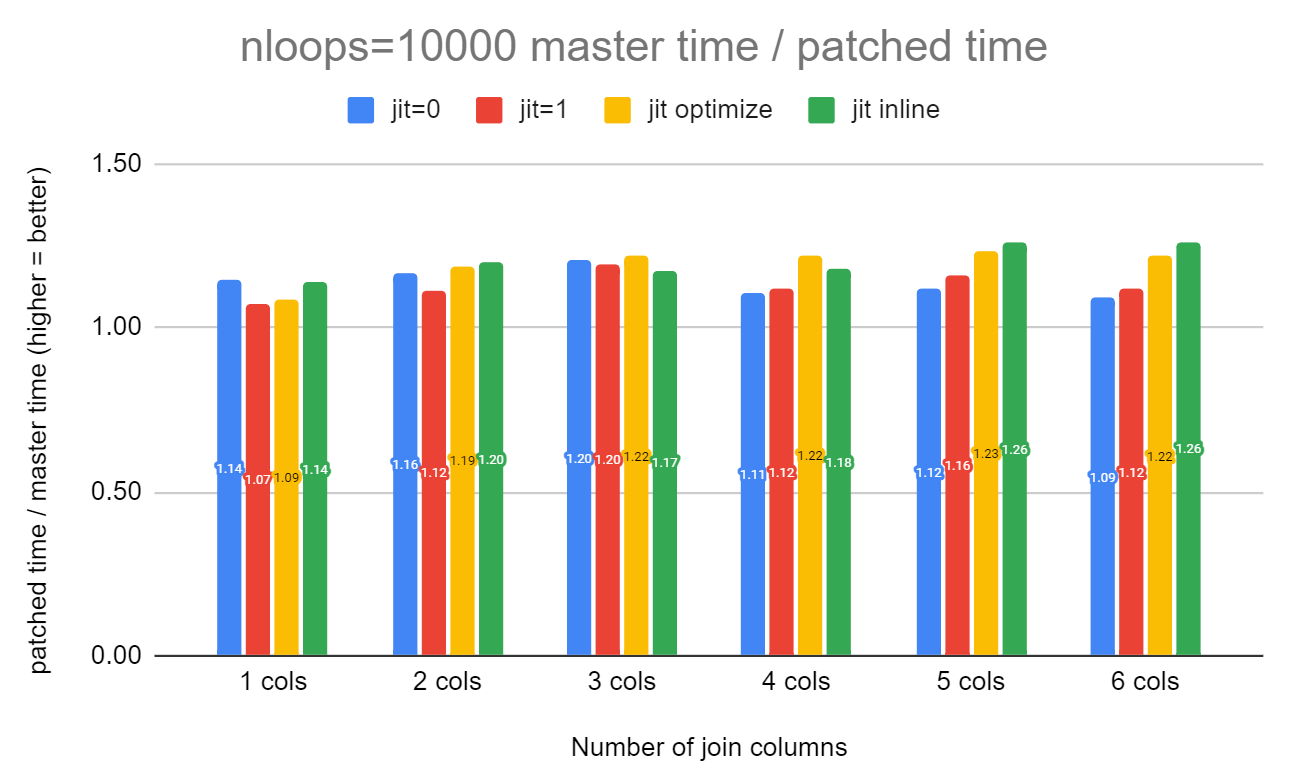
of the hash table. I am seeing much larger performance gains from
that test. Up to 26% faster. Please see the attached .png file for the
results. I've also attached the script I used to get those results.
This time I tried 1-6 join columns and also included the test results
for jit=off, jit=on, jit optimize, jit inline for each of the 6
queries. You can see that with 5 and 6 columns that jit inline was
26% faster than master, but just 14% faster with 1 column. The
smallest improvement was with 1 col with jit=on at just 7% faster.
> - ExecHashGetHashValue, and
> - TupleHashTableHash_internal
>
> .. currently rotate the initial and previous hash values regardless of
> the NULL check. So the rotation should probably be placed before the
> NULL check in NEXT states if you want to preserve the existing
> behavior.
That's my mistake. I think originally I didn't see the sense in
rotating, but you're right. I think not doing that would have (1,
NULL) and (NULL, 1) hash to the same value. Maybe that's ok, but I
think it's much better not to take the risk and keep the behaviour the
same as master. The attached v3 patch does that. I've left the
client_min_messages=debug1 output in the patch for now. I checked the
hash values match with master using a FULL OUTER JOIN with a 3-column
join using 1000 random INTs, 10% of them NULL.
David
| Attachment | Content-Type | Size |
|---|---|---|
| hashjoin_bench.sh.txt | text/plain | 2.0 KB |
|
image/png | 72.4 KB |
| v3-0001-Speed-up-Hash-Join-by-making-ExprStates-hash.patch | application/octet-stream | 37.4 KB |
In response to
- Re: Speed up Hash Join by teaching ExprState about hashing at 2024-07-11 04:47:09 from David Rowley
Responses
- Re: Speed up Hash Join by teaching ExprState about hashing at 2024-08-17 05:14:10 from David Rowley
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Hironobu SUZUKI | 2024-08-15 00:34:34 | Typo in unicode_assigned() document PG17 |
| Previous Message | Jeff Davis | 2024-08-14 23:30:23 | Re: [18] Fix a few issues with the collation cache |