| From: | Melanie Plageman <melanieplageman(at)gmail(dot)com> |
|---|---|
| To: | Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, Peter Geoghegan <pg(at)bowt(dot)ie> |
| Subject: | Eagerly scan all-visible pages to amortize aggressive vacuum |
| Date: | 2024-11-01 23:35:22 |
| Message-ID: | CAAKRu_ZF_KCzZuOrPrOqjGVe8iRVWEAJSpzMgRQs=5-v84cXUg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
An aggressive vacuum of a relation is triggered when its relfrozenxid
is older than vacuum_freeze_table_age XIDs. Aggressive vacuums require
examining every unfrozen tuple in the relation. Normal vacuums can
skip all-visible pages. So a relation with a large number of
all-visible but not all-frozen pages may suddenly have to vacuum an
order of magnitude more pages than the previous vacuum.
In many cases, these all-visible not all-frozen pages are not part of
the working set and must be read in. All of the pages with newly
frozen tuples have to be written out and all of the WAL associated
with freezing and setting the page all-frozen in the VM must be
emitted. This extra I/O can affect performance of the foreground
workload substantially.
The best solution would be to freeze the pages instead of just setting
them all-visible. But we don't want to do this if the page will be
modified again because freezing costs extra I/O.
Last year, I worked on a vacuum patch to try and predict which pages
should be eagerly frozen [1] by building a distribution of page
modification intervals and estimating the probability that a given
page would stay frozen long enough to merit freezing.
While working on it I encountered a problem. Pages set all-visible but
not all-frozen by vacuum and not modified again do not have a
modification interval. As such, the distribution would not account for
an outstanding debt of old, unfrozen pages.
As I thought about the problem more, I realized that even if we could
find a way to include those pages in our model and then predict and
effectively eagerly freeze pages, there will always be pages we miss
and have to be picked up later by an aggressive vacuum.
While it would be best to freeze these pages the first time they are
vacuumed and set all-visible, the write amplification is already being
incurred. This patch proposes to spread it out across multiple
"semi-aggressive" vacuums.
I believe eager scanning is actually a required step toward more
intelligent eager freezing. It is worth noting that eager scanning
should also allow us to lift the restriction on setting pages
all-visible in the VM during on-access pruning. This could enable
index-only scans in more cases.
The approach I take in the attached patch set is built on suggestions
and feedback from both Robert and Andres as well as my own ideas and
research.
It implements a new "semi-aggressive" vacuum. Semi-aggressive vacuums
eagerly scan some number of all-visible but not all-frozen pages in
hopes of freezing them. All-visible pages that are eagerly scanned and
set all-frozen in the visibility map are considered successful eager
scans and those not frozen are considered failed eager scans.
Because we want to amortize our eager scanning across a few vacuums,
we cap the maximum number of successful eager scans to a percentage of
the total number of all-visible but not all-frozen pages in the table
(currently 20%).
We also want to cap the maximum number of failures. We assume that
different areas or "regions" of the relation are likely to contain
similarly aged data. So, if too many blocks are eagerly scanned and
not frozen in a given region of the table, eager scanning is
temporarily suspended.
Since I refer to vacuums that eagerly scan a set number of pages as
"semi-aggressive vacuums," I’ve begun calling those that scan every
unfrozen tuple "fully aggressive vacuums" and those with no eager
scanning, or with permanently disabled eager scanning, "unaggressive
vacuums."
v1 of this feature is attached. The first eight patches in the set are
preliminary.
I've proposed 0001-0003 in this thread [2] -- they boil down to
counting pages set all-frozen in the VM.
0004-0007 are a bit of refactoring to make the code a better shape for
the eager scanning feature.
0008 is a WIP patch to add a more general description of heap
vacuuming to the top of vacuumlazy.c.
0009 is the actual eager scanning feature.
To demonstrate the results, I ran an append-only workload run for over
3 hours on master and with my patch applied. The patched version of
Postgres amortized the work of freezing the all-visible but not
all-frozen pages nicely. The first aggressive vacuum with the patch
was 44 seconds and on master it was 1201 seconds.
patch
LOG: automatic aggressive vacuum of table "history": index scans: 0
vacuum duration: 44 seconds (msecs: 44661).
pages: 0 removed, 27425085 remain, 1104095 scanned (4.03% of
total), 709889 eagerly scanned
frozen: 316544 pages from table (1.15% of total) had 17409920
tuples frozen. 316544 pages set all-frozen in the VM
I/O timings: read: 1160.599 ms, write: 2461.205 ms. approx time
spent in vacuum delay: 16230 ms.
buffer usage: 1105630 hits, 1111898 reads, 646229 newly dirtied,
1750426 dirtied.
WAL usage: 1027099 records, 316566 full page images, 276209780 bytes.
master
LOG: automatic aggressive vacuum of table "history": index scans: 0
vacuum duration: 1201 seconds (msecs: 1201487).
pages: 0 removed, 27515348 remain, 15800948 scanned (57.43% of
total), 15098257 eagerly scanned
frozen: 15096384 pages from table (54.87% of total) had 830247896
tuples frozen. 15096384 pages set all-frozen in the VM
I/O timings: read: 246537.348 ms, write: 73000.498 ms. approx time
spent in vacuum delay: 349166 ms.
buffer usage: 15798343 hits, 15813524 reads, 15097063 newly
dirtied, 31274333 dirtied.
WAL usage: 30733564 records, 15097073 full page images, 11789257631 bytes.
This is because, with the patch, the freezing work is being off-loaded
to earlier vacuums.
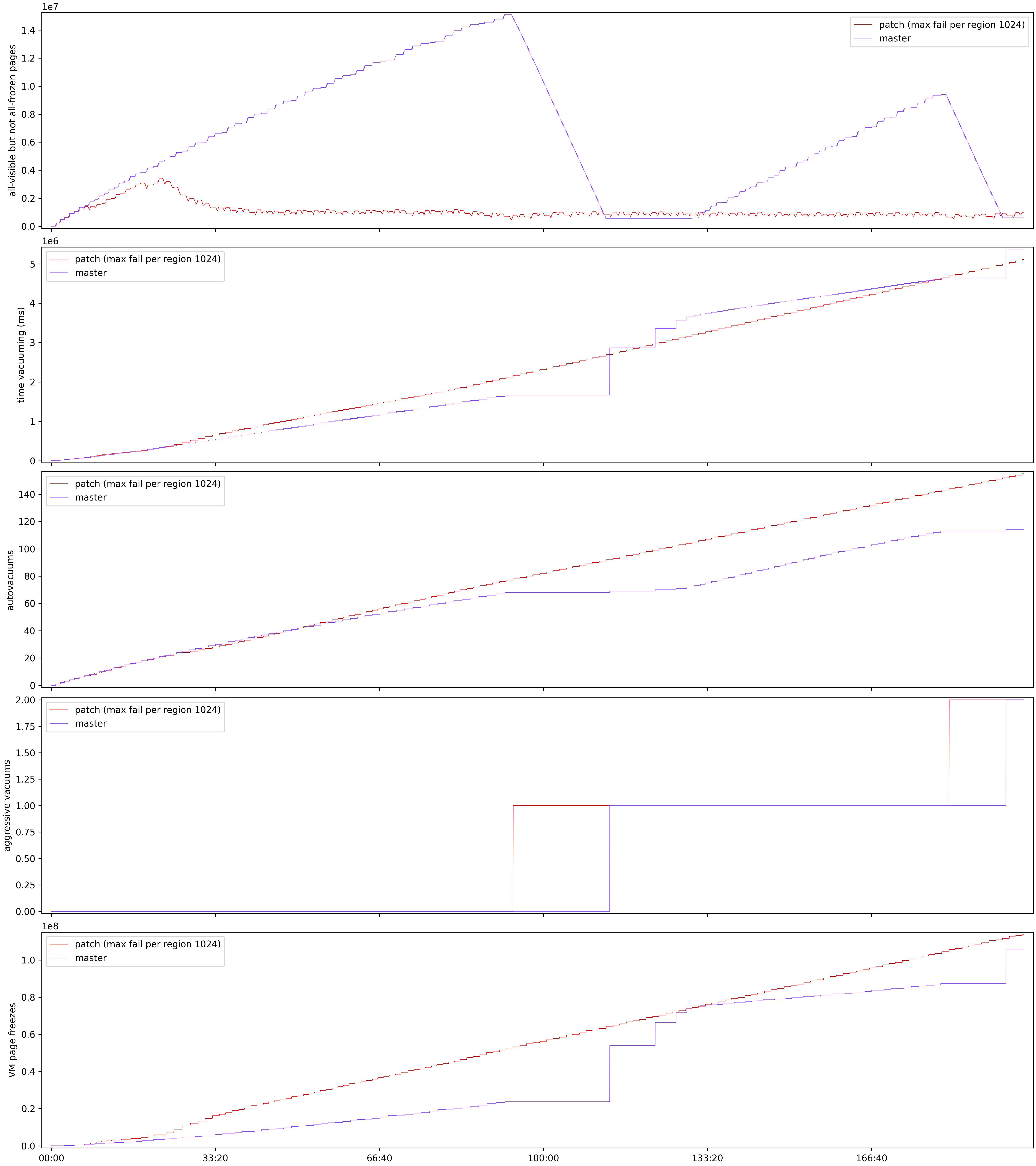
In the attached chart.png, you can see the vm_page_freezes climbing
steadily with the patch, whereas on master, there are sudden spikes
aligned with the aggressive vacuums. You can also see that the number
of pages that are all-visible but not all-frozen grows steadily on
master until the aggressive vacuum. This is vacuum's "backlog" of
freezing work.
In this benchmark, the TPS is rate-limited, but using pgbench
per-statement reports, I calculated that the P99 latency for this
benchmark is 16 ms on master and 1 ms with the patch. Vacuuming pages
sooner decreases vacuum reads and doing the freezing work spread over
more vacuums improves P99 transaction latency.
Below is the comparative WAL volume, checkpointer and background
writer writes, reads and writes done by all other backend types, time
spent vacuuming in milliseconds, and p99 latency. Notice that overall
vacuum IO time is substantially lower with the patch.
version wal cptr_bgwriter_w other_rw vac_io_time p99_lat
patch 770 GB 5903264 235073744 513722 1
master 767 GB 5908523 216887764 1003654 16
(Note that the benchmarks were run on Postgres with a few extra
patches applied to both master and the patch to trigger vacuums more
frequently. I've proposed those here [3].)
I've also run the built-in tpcb-like pgbench workload and confirmed
that it improves the vacuuming behavior on pgbench_history but has
little impact on vacuuming of heavy-update tables like
pgbench_accounts -- depending on how aggressively the eager scanning
is tuned. Which brings me to the TODOs.
I need to do further benchmarking and investigation to determine
optimal failure and success caps -- ones that will work well for all
workloads. Perhaps the failure cap per region should be configurable.
I also need to try other scenarios -- like those in which old data is
deleted -- and determine if the region boundaries should change from
run to run to avoid eager scanning and failing to freeze the same
pages each time.
Also, all my benchmarking so far has been done on compressed
timelines. I tuned Postgres to exhibit the behavior it might normally
exhibit over days or a week in a few hours. As such, I need to start
running long benchmarks to observe the behavior in a more natural
environment.
- Melanie
[1] https://www.postgresql.org/message-id/CAAKRu_b3tpbdRPUPh1Q5h35gXhY%3DspH2ssNsEsJ9sDfw6%3DPEAg%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAAKRu_aJM%2B0Gwoq_%2B-sozMX8QEax4QeDhMvySxRt2ayteXJNCg%40mail.gmail.com
[3] https://www.postgresql.org/message-id/CAAKRu_aj-P7YyBz_cPNwztz6ohP%2BvWis%3Diz3YcomkB3NpYA--w%40mail.gmail.com
| Attachment | Content-Type | Size |
|---|---|---|
| v1-0004-Replace-uses-of-blkno-local-variable-in-lazy_scan.patch | text/x-patch | 2.5 KB |
| v1-0003-Count-pages-set-all-visible-and-all-frozen-in-VM-.patch | text/x-patch | 6.8 KB |
| v1-0001-Rename-LVRelState-frozen_pages.patch | text/x-patch | 3.3 KB |
| v1-0002-Make-visibilitymap_set-return-previous-state-of-v.patch | text/x-patch | 3.2 KB |
| v1-0005-Move-vacuum-VM-buffer-release.patch | text/x-patch | 1.5 KB |
| v1-0006-Remove-superfluous-next_block-local-variable-in-v.patch | text/x-patch | 3.0 KB |
| v1-0007-Make-heap_vac_scan_next_block-return-BlockNumber.patch | text/x-patch | 4.2 KB |
| v1-0008-WIP-Add-more-general-summary-to-vacuumlazy.c.patch | text/x-patch | 1.7 KB |
| v1-0009-Eagerly-scan-all-visible-pages-to-amortize-aggres.patch | text/x-patch | 25.4 KB |
| chart.png | image/png | 572.5 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Noah Misch | 2024-11-01 23:38:29 | Re: Inval reliability, especially for inplace updates |
| Previous Message | Andres Freund | 2024-11-01 22:48:36 | Re: Separate memory contexts for relcache and catcache |
{kind=link}