Re: Add LSN <-> time conversion functionality
| From: | Melanie Plageman <melanieplageman(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(at)vondra(dot)me> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, "Andrey M(dot) Borodin" <x4mmm(at)yandex-team(dot)ru>, Daniel Gustafsson <daniel(at)yesql(dot)se>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andres Freund <andres(at)anarazel(dot)de>, Bharath Rupireddy <bharath(dot)rupireddyforpostgres(at)gmail(dot)com>, Ilya Kosmodemiansky <hydrobiont(at)gmail(dot)com>, Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Subject: | Re: Add LSN <-> time conversion functionality |
| Date: | 2024-08-09 18:13:22 |
| Message-ID: | CAAKRu_YfoQTJnwfJp-D-b_3DaHkMpHMpKYDKRbiZS0T=SGVTfw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Fri, Aug 9, 2024 at 1:03 PM Tomas Vondra <tomas(at)vondra(dot)me> wrote:
>
> On 8/9/24 17:48, Melanie Plageman wrote:
> > On Fri, Aug 9, 2024 at 9:15 AM Melanie Plageman
> > <melanieplageman(at)gmail(dot)com> wrote:
> >>
> >> On Fri, Aug 9, 2024 at 9:09 AM Tomas Vondra <tomas(at)vondra(dot)me> wrote:
> >>>
> >>> I suggest we do the simplest and most obvious algorithm possible, at
> >>> least for now. Focusing on this part seems like a distraction from the
> >>> freezing thing you actually want to do.
> >>
> >> The simplest thing to do would be to pick an arbitrary point in the
> >> past (say one week) and then throw out all the points (except the very
> >> oldest to avoid extrapolation) from before that cliff. I would like to
> >> spend time on getting a new version of the freezing patch on the list,
> >> but I think Robert had strong feelings about having a complete design
> >> first. I'll switch focus to that for a bit so that perhaps you all can
> >> see how I am using the time -> LSN conversion and that could inform
> >> the design of the data structure.
> >
> > I realize this thought didn't make much sense since it is a fixed size
> > data structure. We would have to use some other algorithm to get rid
> > of data if there are still too many points from within the last week.
> >
>
> Not sure I understand. Why would the fixed size of the struct mean we
> can't discard too old data?
Oh, we can discard old data. I was just saying that all of the data
might be newer than the cutoff, in which case we can't only discard
old data if we want to make room for new data.
> > In the adaptive freezing code, I use the time stream to answer a yes
> > or no question. I translate a time in the past (now -
> > target_freeze_duration) to an LSN so that I can determine if a page
> > that is being modified for the first time after having been frozen has
> > been modified sooner than target_freeze_duration (a GUC value). If it
> > is, that page was unfrozen too soon. So, my use case is to produce a
> > yes or no answer. It doesn't matter very much how accurate I am if I
> > am wrong. I count the page as having been unfrozen too soon or I
> > don't. So, it seems I care about the accuracy of data from now until
> > now - target_freeze_duration + margin of error a lot and data before
> > that not at all. While it is true that if I'm wrong about a page that
> > was older but near the cutoff, that might be better than being wrong
> > about a very recent page, it is still wrong.
> >
>
> Yeah. But isn't that a bit backwards? The decision can be wrong because
> the estimate was too off, or maybe it was spot on and we still made a
> wrong decision. That's what happens with heuristics.
>
> I think a natural expectation is that the quality of the answers
> correlates with the accuracy of the data / estimates. With accurate
> results (say we keep a perfect history, with no loss of precision for
> older data) we should be doing the right decision most of the time. If
> not, it's a lost cause, IMHO. And with lower accuracy it'd get worse,
> otherwise why would we need the detailed data.
>
> But now that I think about it, I'm not entirely sure I understand what
> point are you making :-(
My only point was that we really don't need to produce *any* estimate
for a value from before the cutoff. We just need to estimate if it is
before or after. So, while we need to keep enough data to get that
answer right, we don't need very old data at all. Which is different
from how I was thinking about the LSNTimeStream feature before.
On Fri, Aug 9, 2024 at 1:24 PM Tomas Vondra <tomas(at)vondra(dot)me> wrote:
>
> On 8/9/24 15:09, Melanie Plageman wrote:
> >
> > Okay, so as I think about evaluating a few new algorithms, I realize
> > that we do need some sort of criteria. I started listing out what I
> > feel is "reasonable" accuracy and plotting it to see if the
> > relationship is linear/exponential/etc. I think it would help to get
> > input on what would be "reasonable" accuracy.
> >
> > I thought that the following might be acceptable:
> > The first column is how old the value I am looking for actually is,
> > the second column is how off I am willing to have the algorithm tell
> > me it is (+/-):
> >
> > 1 second, 1 minute
> > 1 minute, 10 minute
> > 1 hour, 1 hour
> > 1 day, 6 hours
> > 1 week, 12 hours
> > 1 month, 1 day
> > 6 months, 1 week
> >
>
> I think the question is whether we want to make this useful for other
> places and/or people, or if it's fine to tailor this specifically for
> the freezing patch.
>
> If the latter (specific to the freezing patch), I don't see why would it
> matter what we think - either it works for the patch, or not.
I think the best way forward is to make it useful for the freezing
patch and then, if it seems like exposing it makes sense, we can do
that and properly document what to expect.
> But if we want to make it more widely useful, I find it a bit strange
> the relative accuracy *increases* for older data. I mean, we start with
> relative error 6000% (60s/1s) and then we get to relative error ~4%
> (1w/24w). Isn't that a bit against the earlier discussion on needing
> better accuracy for recent data? Sure, the absolute accuracy is still
> better (1m <<< 1w). And if this is good enough for the freezing ...
I was just writing out what seemed intuitively like something I would
be willing to tolerate as a user. But you are right that doesn't make
sense -- for the accuracy to go up for older data. I just think being
months off for any estimate seems bad no matter how old the data is --
which is probably why I felt like 1 week of accuracy for data 6 months
old seemed like a reasonable tolerance. But, perhaps that isn't
useful.
Also, I realized that my "calculate the error area" method strongly
favors keeping older data. Once you drop a point, the area between the
two remaining points (on either side of it) will be larger because the
distance between them is greater with the dropped point. So there is a
strong bias toward dropping newer data. That seems bad.
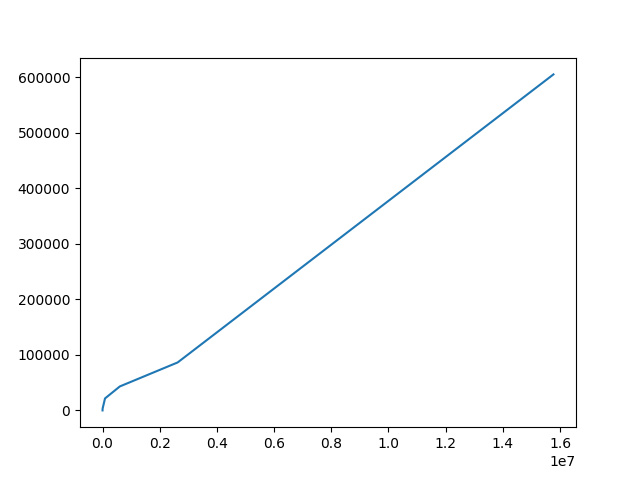
> > Column 1 over column 2 produces a line like in the attached pic. I'd
> > be interested in others' opinions of error tolerance.
>
> I don't understand what the axes on the chart are :-( Does "A over B"
> mean A is x-axis or y-axis?
Yea, that was confusing. A over B is the y axis so you could see the
ratios and x is just their position in the array (so meaningless).
Attached is A on the x axis and B on the y axis.
- Melanie
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 21.4 KB |
In response to
- Re: Add LSN <-> time conversion functionality at 2024-08-09 17:24:46 from Tomas Vondra
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Nathan Bossart | 2024-08-09 18:17:35 | Re: fix CRC algorithm in WAL reliability docs |
| Previous Message | Tomas Vondra | 2024-08-09 17:24:46 | Re: Add LSN <-> time conversion functionality |