Re: GIN improvements part2: fast scan
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: GIN improvements part2: fast scan |
| Date: | 2014-01-28 03:54:56 |
| Message-ID: | 52E72A10.5040908@fuzzy.cz |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 27.1.2014 16:30, Alexander Korotkov wrote:
> On Mon, Jan 27, 2014 at 2:32 PM, Alexander Korotkov
> <aekorotkov(at)gmail(dot)com <mailto:aekorotkov(at)gmail(dot)com>> wrote:
>
> I attach two patches which rollback these two features (sorry for awful
> quality of second). Native consistent function accelerates thing
> significantly, as expected. Tt seems that sorting entries have almost no
> effect. However it's still not as fast as initial fast-scan:
>
> # select count(*) from fts_test where fti @@ plainto_tsquery('english',
> 'gin index select');
> count
> ───────
> 627
> (1 row)
>
> Time: 5,381 ms
>
> Tomas, could you rerun your tests with first and both these patches
> applied against patches by Heikki?
Done, and the results are somewhat disappointing.
I've generated 1000 queries with either 3 or 6 words, based on how often
they occur in the documents. For example 1% means there's 1% of
documents containing the word. In this case, I've used ranges 0-2%, 1-3%
and 3-9%.
Which gives six combinations
| 0-2% | 1-3% | 3-9% |
--------------------------------
3 words | | | |
--------------------------------
6 words | | | |
--------------------------------
Each word had ~5% probability to be negated (i.e. "!" in front of it).
So these queries are a bit different than the ones I ran yesterday.
Then I ran those scripts on:
* 9.3
* 9.4 with Heikki's patches (9.4-heikki)
* 9.4 with Heikki's and first patch (9.4-alex-1)
* 9.4 with Heikki's and both patches (9.4-alex-2)
I've always created a new DB, loaded the data, done VACUUM (FREEZE,
ANALYZE) and then ran the script 5x but only measured the fifth run.
The full results are available here (and attached as ODT, but just the
numbers without the charts)
https://docs.google.com/spreadsheet/ccc?key=0Alm8ruV3ChcgdHJfZTdOY2JBSlkwZjNuWGlIaGM0REE
On all the charts the x-axis is "how long it took without the patch" and
y-axis means "how much longer it took with the patch". 1 means exactly
the same, >1 slower, <1 faster. Sometimes one (or both) of the axes is
log-scale. The durations are in microseconds (i.e. 1e-6 sec).
I'll analyze the results for 3-words first.
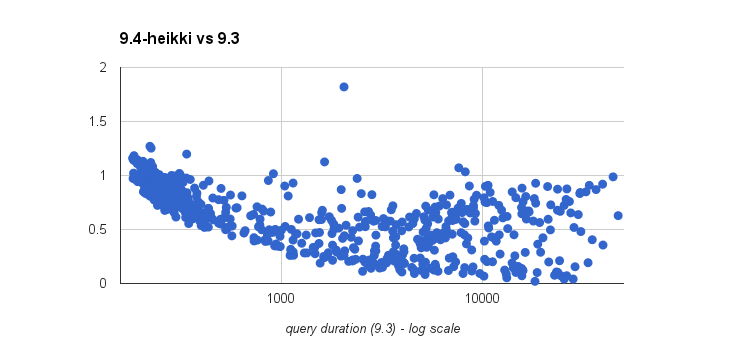
The Heikki's patch seems fine, at least compared to 9.3. See for example
the heikki-vs-9.3.png image. This is the case with 3 words, each
contained in less than 2% of documents (i.e. rare words). Vast majority
of the queries is much faster, and the ~1.0 results are below 1
milisecond, which is somewhat tricky to measure.
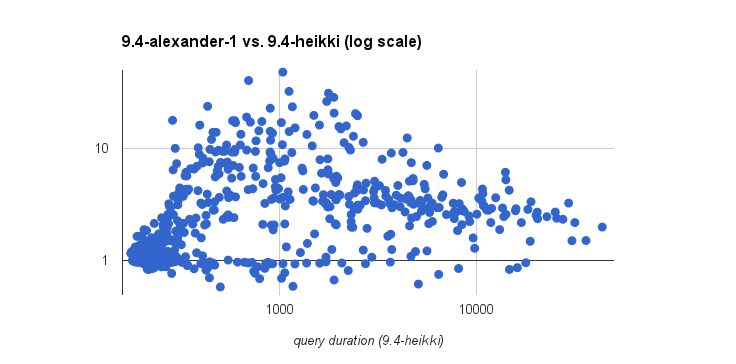
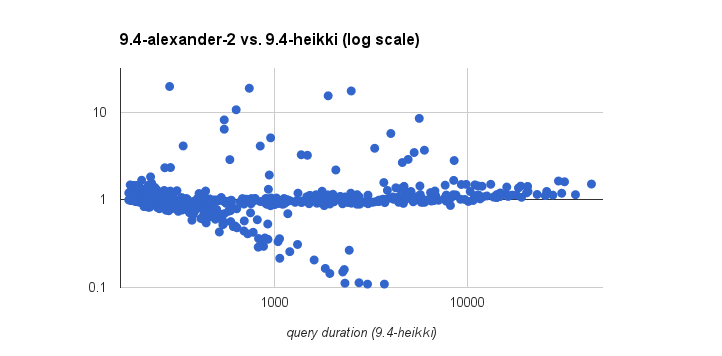
Now, see alexander-1.png / alexander-2.png, for one / both of the
patches, compared to results with Heikki's patches. Not really good,
IMHO, especially for the first patch - most of the queries is much
slower, even by an order of magnitude. The second patch fixes the worst
cases, but does not really make it better than 9.4-heikki.
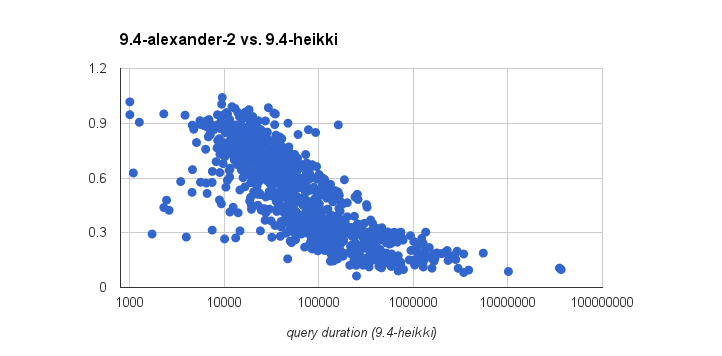
It however gets better as the words become more common. See for example
alexander-common-words.png - which once again compares 9.4-alex-1 vs.
9.4-heikki on 3 words in the 3-9% range. This time the performance is
rather consistently better.
On 6 words the results are similar, i.e bad with rare words but getting
better on the more common ones. Except that in this case it never gets
better than 9.4-heikki.
I can provide the queries but without the dataset I'm testing this on,
that's pretty useless. I'll try to analyze this a bit more later today,
but I'm afraid I don't have the necessary insight.
regards
Tomas
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 23.9 KB |
|
image/png | 26.6 KB |
|
image/png | 18.4 KB |
|
image/png | 23.0 KB |
In response to
- Re: GIN improvements part2: fast scan at 2014-01-27 15:30:05 from Alexander Korotkov
Responses
- Re: GIN improvements part2: fast scan at 2014-01-28 07:29:24 from Heikki Linnakangas
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Fujii Masao | 2014-01-28 03:56:42 | pg_basebackup and pg_stat_tmp directory |
| Previous Message | Sawada Masahiko | 2014-01-28 03:50:48 | Re: Fix comment typo in /src/backend/command/cluster.c |