Re: gaussian distribution pgbench
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Gregory Smith <gregsmithpgsql(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, Peter Geoghegan <pg(at)heroku(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Peter Eisentraut <peter_e(at)gmx(dot)net>, Fabien COELHO <coelho(at)cri(dot)ensmp(dot)fr> |
| Subject: | Re: gaussian distribution pgbench |
| Date: | 2014-01-14 06:52:17 |
| Message-ID: | 52D4DEA1.3050900@lab.ntt.co.jp |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
I revise my gaussian pgbench patch which wss requested from community.
* Changes
- Support custom script.
- "\setgaussian" is generating gaussian distribute random number.
- ex) \setgaussian [var] [min] [max] [stddev_threshold]
- We can use mixture model in multiple custom scripts.
- Delete short option "-g", and add long options ”--gaussian"
- Refactoring getrand() interface
> - getrand(TState *thread, int64 min, int64 max)
> + getrand(TState *thread, int64 min, int64 max, DistType dist_type, double value1)
- We can easy to add other random distribution algorithms. Please see detail
design in attached patch.
Febien COELHO wrote:
>> From a probabilistic point of view, it seems to me that a randomized
> (discretized) exponential would be more significant to model a server load.
>
> \setexp var min max lambda...
I can create randomized exponential distribution under following. It is very easy.
double rand_exp( double lambda ){
return -log(Uniform(0,1))/lambda;
}
If community wants this, I will add this function in my patch.
Gavin Flower wrote:
> Curious, wouldn't the common usage pattern tend to favour a skewed distribution,
> such as the Poisson Distribution (it has been over 40 years since I studied
> this area, so there may be better candidates).
The difference between Poisson distribution and Gaussian distribution is discrete
or not.
In my gaussian algorithm, first generating continuos gaussian distribution, next
projection to integer values which are each record, it will be discrete value.
Therefore, it will be almost simular with Poisson distribution. And when we set
larger standard deviations(higher 10), it will be created better approximation of
Poisson distribution.
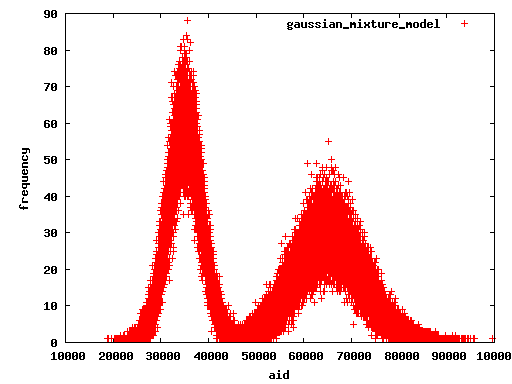
Attached sql files are for custom scripts which are different distribution. It
realize mixture distribuion benchmark. And attached graph is the result.
[example command]
$pgbench -f file1.sql file2.sql
If you have more some comment, please send me.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
| gaussian_pgbench_v3.patch | text/x-diff | 16.9 KB |
| file1.sql | text/plain | 347 bytes |
| file2.sql | text/plain | 575 bytes |
|
image/png | 4.3 KB |
In response to
- Re: gaussian distribution pgbench at 2013-12-20 01:23:25 from Gregory Smith
Responses
- Re: gaussian distribution pgbench at 2014-02-09 12:32:54 from Fabien COELHO
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Jeevan Chalke | 2014-01-14 06:52:30 | Re: [PATCH] Filter error log statements by sqlstate |
| Previous Message | Amit Kapila | 2014-01-14 06:16:11 | Re: Performance Improvement by reducing WAL for Update Operation |