| From: | Yuya Watari <watari(dot)yuya(at)gmail(dot)com> |
|---|---|
| To: | David Rowley <dgrowleyml(at)gmail(dot)com> |
| Cc: | Andrey Lepikhov <a(dot)lepikhov(at)postgrespro(dot)ru>, Ashutosh Bapat <ashutosh(dot)bapat(dot)oss(at)gmail(dot)com>, Thom Brown <thom(at)linux(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Zhang Mingli <zmlpostgres(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Re: [PoC] Reducing planning time when tables have many partitions |
| Date: | 2023-08-25 07:39:16 |
| Message-ID: | CAJ2pMkZk-Nr=yCKrGfGLu35gK-D179QPyxaqtJMUkO86y1NmSA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello,
On Wed, Aug 9, 2023 at 8:54 PM David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
> I think the best way to move this forward is to explore not putting
> partitioned table partitions in EMs and instead see if we can
> translate to top-level parent before lookups. This might just be too
> complex to translate the Exprs all the time and it may add overhead
> unless we can quickly determine somehow that we don't need to attempt
> to translate the Expr when the given Expr is already from the
> top-level parent. If that can't be made to work, then maybe that shows
> the current patch has merit.
Based on your suggestion, I have experimented with not putting child
EquivalenceMembers in an EquivalenceClass. I have attached a new
patch, v20, to this email. The following is a summary of v20.
* v20 has been written from scratch.
* In v20, EquivalenceClass->ec_members no longer has any child
members. All of ec_members are now non-child. Instead, the child
EquivalenceMembers are in the RelOptInfos.
* When child EquivalenceMembers are required, 1) we translate the
given Relids to their top-level parents, and 2) if some parent
EquivalenceMembers' Relids match the translated top-level ones, we get
the child members from the RelOptInfo.
* With the above change, ec_members has a few members, which leads to
a significant performance improvement. This is the core part of the
v20 optimization.
* My experimental results show that v20 performs better for both small
and large sizes. For small sizes, v20 is clearly superior to v19. For
large sizes, v20 performs as well as v19.
* At this point, I don't know if we should switch to the v20 method.
v20 is just a new proof of concept with much room for improvement. It
is important to compare two different methods of v19 and v20 and
discuss the best strategy.
1. Key idea of v20
I have attached a patch series consisting of two patches. v20-0001 and
v20-0002 are for optimizations regarding EquivalenceClasses and
RestrictInfos, respectively. v20-0002 is picked up from v19. Most of
my new optimizations are in v20-0001.
As I wrote above, the main change in v20-0001 is that we don't add
child EquivalenceMembers to ec_members. I will describe how v20 works.
First of all, take a look at the code of get_eclass_for_sort_expr().
Its comments are helpful for understanding my idea. Traditionally, we
have searched EquivalenceMembers matching the request as follows. This
was a very slow linear search when there were many members in the
list.
===== Master =====
foreach(lc2, cur_ec->ec_members)
{
EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
/*
* Ignore child members unless they match the request.
*/
if (cur_em->em_is_child &&
!bms_equal(cur_em->em_relids, rel))
continue;
/*
* Match constants only within the same JoinDomain (see
* optimizer/README).
*/
if (cur_em->em_is_const && cur_em->em_jdomain != jdomain)
continue;
if (opcintype == cur_em->em_datatype &&
equal(expr, cur_em->em_expr))
return cur_ec; /* Match! */
}
==================
v20 addressed this problem by not adding child members to ec_members.
Since there are few members in the list, we can speed up the search.
Of course, we still need child members. Previously, child members have
been made and added to ec_members in
add_child_[join_]rel_equivalences(). Now, in v20, we add them to
child_[join]rel instead of ec_members. The following is the v20's
change.
===== v20 =====
@@ -2718,9 +2856,20 @@ add_child_rel_equivalences(PlannerInfo *root,
top_parent_relids);
new_relids = bms_add_members(new_relids, child_relids);
- (void) add_eq_member(cur_ec, child_expr, new_relids,
- cur_em->em_jdomain,
- cur_em, cur_em->em_datatype);
+ child_em = make_eq_member(cur_ec, child_expr, new_relids,
+ cur_em->em_jdomain,
+ cur_em, cur_em->em_datatype);
+ child_rel->eclass_child_members = lappend(child_rel->eclass_child_members,
+ child_em);
+
+ /*
+ * We save the knowledge that 'child_em' can be translated from
+ * 'child_rel'. This knowledge is useful for
+ * add_transformed_child_version() to find child members from the
+ * given Relids.
+ */
+ cur_em->em_child_relids = bms_add_member(cur_em->em_child_relids,
+ child_rel->relid);
/* Record this EC index for the child rel */
child_rel->eclass_indexes = bms_add_member(child_rel->eclass_indexes, i);
===============
In many places, we need child EquivalenceMembers that match the given
Relids. To get them, we first find the top-level parents of the given
Relids by calling find_relids_top_parents(). find_relids_top_parents()
replaces all of the Relids as their top-level parents. During looping
over ec_members, we check if the children of an EquivalenceMember can
match the request (top-level parents are needed in this checking). If
the children can match, we get child members from RelOptInfos. These
techniques are the core of the v20 solution. The next change does what
I mentioned now.
===== v20 =====
@@ -599,6 +648,17 @@ get_eclass_for_sort_expr(PlannerInfo *root,
EquivalenceMember *newem;
ListCell *lc1;
MemoryContext oldcontext;
+ Relids top_parent_rel;
+
+ /*
+ * First, we translate the given Relids to their top-level parents. This is
+ * required because an EquivalenceClass contains only parent
+ * EquivalenceMembers, and we have to translate top-level ones to get child
+ * members. We can skip such translations if we now see top-level ones,
+ * i.e., when top_parent_rel is NULL. See the find_relids_top_parents()'s
+ * definition for more details.
+ */
+ top_parent_rel = find_relids_top_parents(root, rel);
/*
* Ensure the expression exposes the correct type and collation.
@@ -632,16 +694,35 @@ get_eclass_for_sort_expr(PlannerInfo *root,
if (!equal(opfamilies, cur_ec->ec_opfamilies))
continue;
- foreach(lc2, cur_ec->ec_members)
+ /*
+ * When we have to see child EquivalenceMembers, we get and add them to
+ * 'members'. We cannot use foreach() because the 'members' may be
+ * modified during iteration.
+ */
+ members = cur_ec->ec_members;
+ modified = false;
+ for (i = 0; i < list_length(members); i++)
{
- EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
+ EquivalenceMember *cur_em =
list_nth_node(EquivalenceMember, members, i);
+
+ /*
+ * If child EquivalenceMembers may match the request, we add and
+ * iterate over them.
+ */
+ if (unlikely(top_parent_rel != NULL) && !cur_em->em_is_child &&
+ bms_equal(cur_em->em_relids, top_parent_rel))
+ add_child_rel_equivalences_to_list(root, cur_ec, cur_em, rel,
+ &members, &modified);
/*
* Ignore child members unless they match the request.
*/
- if (cur_em->em_is_child &&
- !bms_equal(cur_em->em_relids, rel))
- continue;
+ /*
+ * If this EquivalenceMember is a child, i.e., translated above,
+ * it should match the request. We cannot assert this if a request
+ * is bms_is_subset().
+ */
+ Assert(!cur_em->em_is_child || bms_equal(cur_em->em_relids, rel));
/*
* Match constants only within the same JoinDomain (see
===============
The main concern was the overhead of getting top-level parents. If the
given Relids are already top-level, such an operation can be a major
bottleneck. I addressed this issue with a simple null check. v20 saves
top-level parent Relids to PlannerInfo's array. If there are no
children, v20 sets this array to null, and find_relids_top_parents()
can quickly conclude that the given Relids are top-level. For more
details, see the find_relids_top_parents() in pathnode.h (partially
quoted below).
===== v20 =====
@@ -323,6 +323,24 @@ extern Relids min_join_parameterization(PlannerInfo *root,
+#define find_relids_top_parents(root, relids) \
+ (likely((root)->top_parent_relid_array == NULL) \
+ ? NULL : find_relids_top_parents_slow(root, relids))
+extern Relids find_relids_top_parents_slow(PlannerInfo *root, Relids relids);
===============
2. Experimental results
I conducted experiments to test the performance of v20.
2.1. Small size cases (make installcheck)
When I worked with you on optimizing Bitmapset operations, we used
'make installcheck' to check degradation in planning [1]. I did the
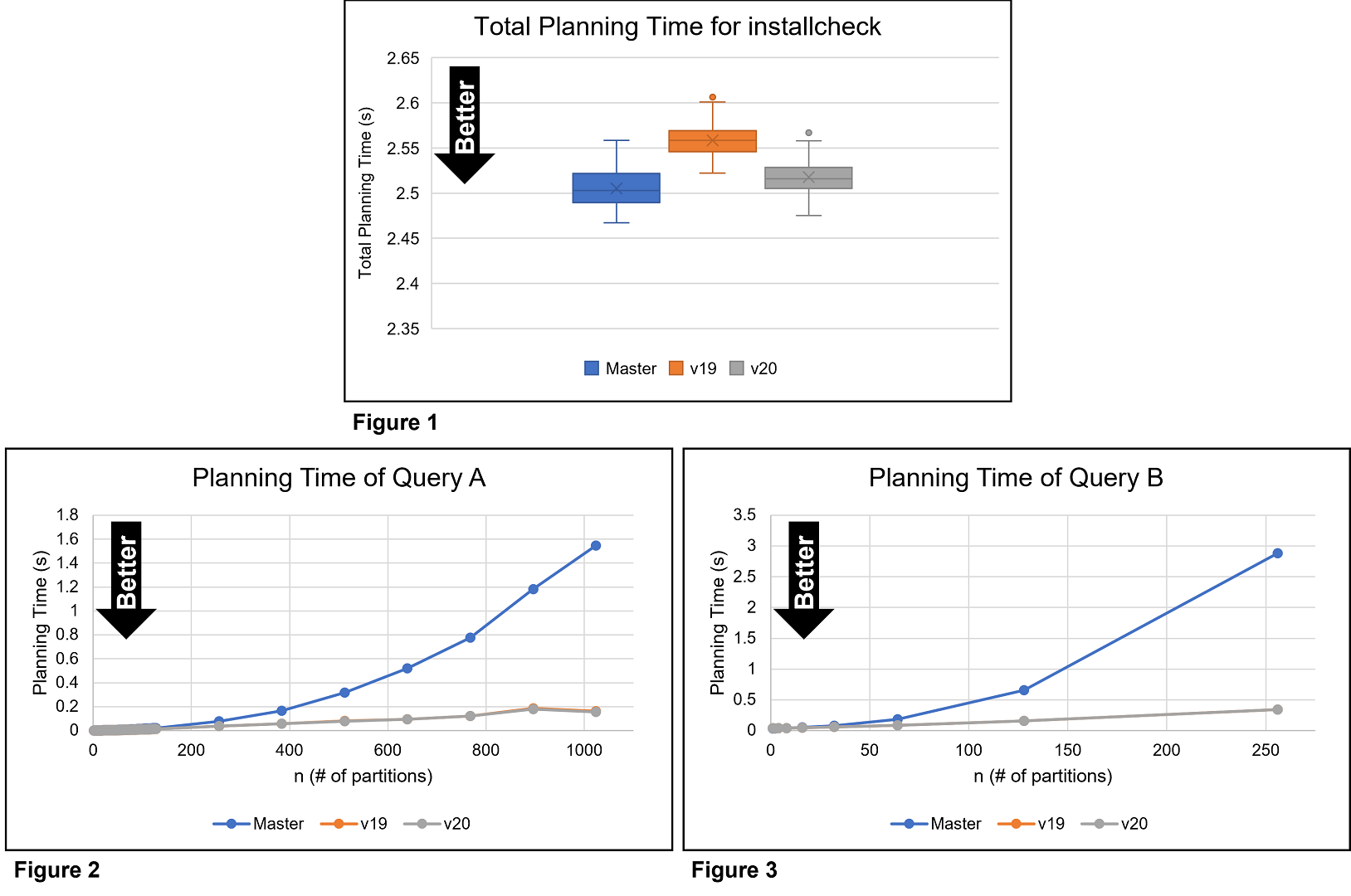
same for v19 and v20. Figure 1 and Tables 1 and 2 are the results.
They show that v20 is clearly superior to v19. The degradation of v20
was only 0.5%, while that of v19 was 2.1%. Figure 1 shows that the
0.5% slowdown is much smaller than its variance.
Table 1: Total Planning Time for installcheck (seconds)
-----------------------------------------
| Mean | Median | Stddev
-----------------------------------------
Master | 2.505161 | 2.503110 | 0.019775
v19 | 2.558466 | 2.558560 | 0.017320
v20 | 2.517806 | 2.516081 | 0.016932
-----------------------------------------
Table 2: Speedup for installcheck (higher is better)
----------------------
| Mean | Median
----------------------
v19 | 97.9% | 97.8%
v20 | 99.5% | 99.5%
----------------------
2.2. Large size cases (queries A and B)
I evaluated v20 with the same queries I have used in this thread. The
queries, Queries A and B, are attached in [2]. Both queries join
partitioned tables. Figures 2 and 3 and the following tables show the
results. v20 performed as well as v19 for large sizes. v20 achieved a
speedup of about x10. There seems to be some regression for small
sizes.
Table 3: Planning time of Query A
(n: the number of partitions of each table)
(lower is better)
------------------------------------------
n | Master (ms) | v19 (ms) | v20 (ms)
------------------------------------------
1 | 0.713 | 0.730 | 0.737
2 | 0.792 | 0.814 | 0.815
4 | 0.955 | 0.982 | 0.987
8 | 1.291 | 1.299 | 1.335
16 | 1.984 | 1.951 | 1.992
32 | 3.991 | 3.720 | 3.778
64 | 7.701 | 6.003 | 6.891
128 | 21.118 | 13.988 | 12.861
256 | 77.405 | 37.091 | 37.294
384 | 166.122 | 56.748 | 57.130
512 | 316.650 | 79.942 | 78.692
640 | 520.007 | 94.030 | 93.772
768 | 778.314 | 123.494 | 123.207
896 | 1182.477 | 185.422 | 179.266
1024 | 1547.897 | 161.104 | 155.761
------------------------------------------
Table 4: Speedup of Query A (higher is better)
------------------------
n | v19 | v20
------------------------
1 | 97.7% | 96.7%
2 | 97.3% | 97.2%
4 | 97.3% | 96.8%
8 | 99.4% | 96.7%
16 | 101.7% | 99.6%
32 | 107.3% | 105.6%
64 | 128.3% | 111.8%
128 | 151.0% | 164.2%
256 | 208.7% | 207.6%
384 | 292.7% | 290.8%
512 | 396.1% | 402.4%
640 | 553.0% | 554.5%
768 | 630.2% | 631.7%
896 | 637.7% | 659.6%
1024 | 960.8% | 993.8%
------------------------
Table 5: Planning time of Query B
-----------------------------------------
n | Master (ms) | v19 (ms) | v20 (ms)
-----------------------------------------
1 | 37.044 | 38.062 | 37.614
2 | 35.839 | 36.804 | 36.555
4 | 38.202 | 37.864 | 37.977
8 | 42.292 | 41.023 | 41.210
16 | 51.867 | 46.481 | 46.477
32 | 80.003 | 57.329 | 57.363
64 | 185.212 | 87.124 | 88.528
128 | 656.116 | 157.236 | 160.884
256 | 2883.258 | 343.035 | 340.285
-----------------------------------------
Table 6: Speedup of Query B (higher is better)
-----------------------
n | v19 | v20
-----------------------
1 | 97.3% | 98.5%
2 | 97.4% | 98.0%
4 | 100.9% | 100.6%
8 | 103.1% | 102.6%
16 | 111.6% | 111.6%
32 | 139.6% | 139.5%
64 | 212.6% | 209.2%
128 | 417.3% | 407.8%
256 | 840.5% | 847.3%
-----------------------
3. Future works
3.1. Redundant memory allocation of Lists
When we need child EquivalenceMembers in a loop over ec_members, v20
adds them to the list. However, since we cannot modify the ec_members,
v20 always copies it. In most cases, there are only one or two child
members, so this behavior is a waste of memory and time and not a good
idea. I didn't address this problem in v20 because doing so could add
much complexity to the code, but it is one of the major future works.
I suspect that the degradation of Queries A and B is due to this
problem. The difference between 'make installcheck' and Queries A and
B is whether there are partitioned tables. Most of the tests in 'make
installcheck' do not have partitions, so find_relids_top_parents()
could immediately determine the given Relids are already top-level and
keep degradation very small. However, since Queries A and B have
partitions, too frequent allocations of Lists may have caused the
regression. I hope we can reduce the degradation by avoiding these
memory allocations. I will continue to investigate and fix this
problem.
3.2. em_relids and pull_varnos
I'm sorry that v20 did not address your 1st concern regarding
em_relids and pull_varnos. I will try to look into this.
3.3. Indexes for RestrictInfos
Indexes for RestrictInfos are still in RangeTblEntry in v20-0002. I
will also investigate this issue.
3.4. Correctness
v20 has passed all regression tests in my environment, but I'm not so
sure if v20 is correct.
4. Conclusion
I wrote v20 based on a new idea. It may have a lot of problems, but it
has advantages. At least it solves your 3rd concern. Since we iterate
Lists instead of Bitmapsets, we don't have to introduce an iterator
mechanism. My experiment showed that the 'make installcheck'
degradation was very small. For the 2nd concern, v20 no longer adds
child EquivalenceMembers to ec_members. I'm sorry if this is not what
you intended, but it effectively worked. Again, v20 is a new proof of
concept. I hope the v20-based approach will be a good alternative
solution if we can overcome several problems, including what I
mentioned above.
[1] https://www.postgresql.org/message-id/CAApHDvo68m_0JuTHnEHFNsdSJEb2uPphK6BWXStj93u_QEi2rg%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAJ2pMkYcKHFBD_OMUSVyhYSQU0-j9T6NZ0pL6pwbZsUCohWc7Q%40mail.gmail.com
--
Best regards,
Yuya Watari
| Attachment | Content-Type | Size |
|---|---|---|
| v20-0001-Speed-up-searches-for-child-EquivalenceMembers.patch | application/octet-stream | 61.3 KB |
| v20-0002-Introduce-indexes-for-RestrictInfo.patch | application/octet-stream | 31.6 KB |
| figures.png | image/png | 147.5 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Jim Jones | 2023-08-25 08:27:08 | Re: [PATCH] Add XMLText function (SQL/XML X038) |
| Previous Message | Pavel Stehule | 2023-08-25 07:12:20 | Re: broken master regress tests |
{kind=link}