More tuple deformation speedups
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | More tuple deformation speedups |
| Date: | 2024-10-30 21:27:18 |
| Message-ID: | CAApHDvo9e0XG71WrefYaRv5n4xNPLK4k8LjD0mSR3c9KR2vi2Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
While working on the other tuple deformation speedup patches in [1], I
noticed that the code in slot_deform_heap_tuple() is a bit "overly
branchy" and could be done more efficiently with the following
assumptions:
1. We only need to switch from !slow mode into slow mode, never the
other way around (for a given tuple)
2. We know upfront if a tuple contains any NULLs by checking the
infomask for HEAP_HASNULL.
Because of #1, we can lay the code out as two loops, the first of
which is coded to assume we're not in slow mode and anywhere we do "if
(!slow)" we can get rid of those checks as we already know we're not
in slow mode. Instead of having those checks, we can just break out
of the first loop if we hit a NULL or variable length attribute and
fall into a 2nd loop which has all of the "if (!slow)" branches
eliminated and does not have any code to cache the offset.
Because of #2, we can forego checking the "if (hasnulls &&
att_isnull(attnum, bp))" for every single attribute. If "hasnulls" is
false, there's no need to check that on every loop. We can simply have
a dedicated loop that handles !slow and !hasnulls. I think having no
nulls in a tuple is very common, so seems worthwhile having a version
without the NULL checks.
I think the best way to form this as C code is to have an always
inline function that we call with various combinations of "slow" and
"hasnulls" and allow the compiler to emit specialised code for the
various scenarios. I've done this in the attached and made it so there
are 3 specialisations 1) !slow && !hasnulls 2) !slow && hasnulls 3)
slow && (hasnulls || !hasnulls).
(I resisted having a dedicated version for slow && !hasnulls. It might
be worthwhile having that.)
I did some benchmarking of this with 3 different scenarios and with
each scenario, I did a count(col) on the 16th column in the given
table. The variation between each of the three test comes from the
first column in the table:
* t1: Zero NULLs and all columns fixed-width types
* t2: First column has a NULL value. Other columns on all rows are not
null. (forces slow mode early on)
* t3: First column is a varlena type all other columns fixed-width. No
nulls anywhere. (also forces slow mode early on)
I ran the benchmark using the attached script on 3 different machines
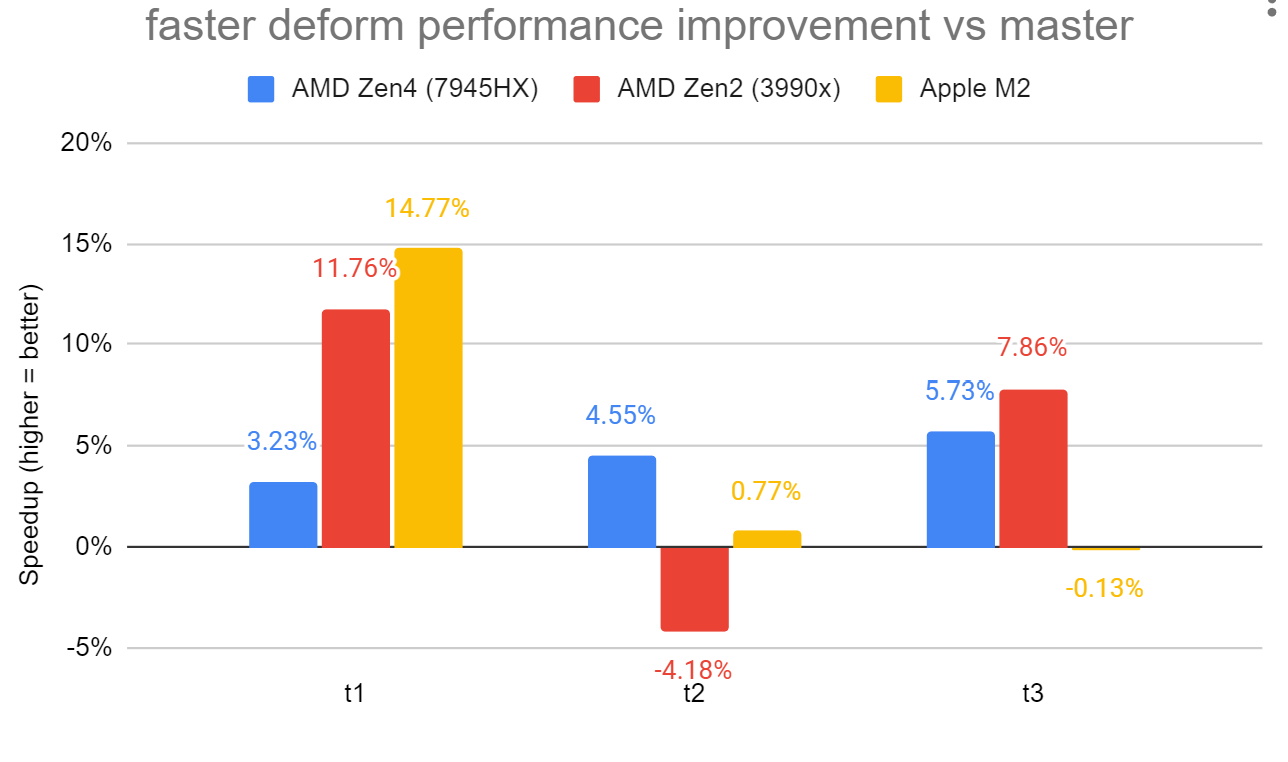
and graphed them. See attached deform_specialisations_bench.png.
There is a slowdown on test 2 with the Zen2 machine. The other patches
I have in [2] help reduce the amount of code required to figure out
the attribute alignment, so that helps to reduce the amount of
additional code that the compiler emits when I apply all patches
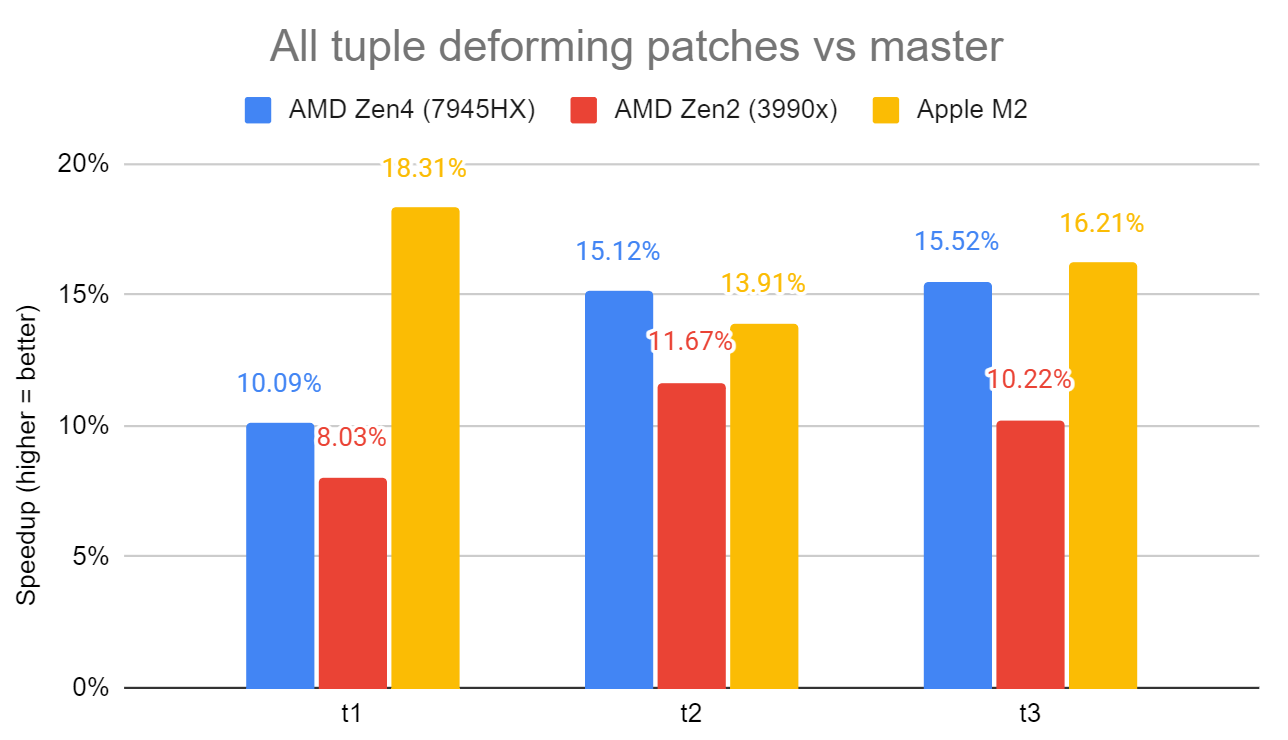
together. With that, the Zen2 regression goes away and overall results
on all 3 machines look nicer. See attached all_patches_bench.png
The attached v1-0001 does not apply cleanly on top of the patches in
[2], so I've also attached a version that does for anyone who wants to
try it out with the other patches.
I'd like to go ahead with the patches in [2] first then loop back
around to this one again. I'm posting here rather than overloading
that other thread with the new patch.
David
[1] https://postgr.es/m/CAApHDvrBztXP3yx%3DNKNmo3xwFAFhEdyPnvrDg3%3DM0RhDs%2B4vYw%40mail.gmail.com
[2] https://postgr.es/m/CAApHDvpwd76-goJ3J-g_VQEzhqqb7F-3Kd70LXNrS23UHYSLBg%40mail.gmail.com
| Attachment | Content-Type | Size |
|---|---|---|
| deform_test2.sh.txt | text/plain | 2.1 KB |
|
image/png | 67.4 KB |
| v1-0001-Speedup-tuple-deformation-with-additional-functio.patch | application/octet-stream | 9.1 KB |
|
image/png | 70.1 KB |
| version_based_atop_of_other_patches.patch.txt | text/plain | 8.0 KB |
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Devulapalli, Raghuveer | 2024-10-30 21:36:00 | RE: Popcount optimization using AVX512 |
| Previous Message | Peter Geoghegan | 2024-10-30 21:26:49 | Re: Having problems generating a code coverage report |